My Devember 2021 project is to build a web crawler that can be deployed to a pool of machines and crawl multiple domains in parallel.
I don’t expect this to do anything that couldn’t be accomplished using existing software. I see this primarily as a way for me to learn about designing, developing and deploying microservices.
Technologies
- C# (.NET 6) for the crawler
- Kubernetes for deployment
- React for the front end (if I get that far)
Features
- Crawl multiple domains in parallel
- Rate limiting, to prevent the same domain getting hammered with requests
- Should respect robots.txt
- Limit the pages that get crawled based on:
- Crawl depth
- A list of included/excluded domains
- Pause/resume crawling
- View/download crawl results
Stretch goals
- Web front end for viewing / downloading crawled pages
- Render / execute javascript (to allow single page apps to be crawled)
Github link:
Also, the project doesn’t have a name yet. I’m open to suggestions!
3 Likes
Progress update
I’ve pushed my initial code to Github. I decided it would be best to build and test each component of the crawler together in a simple console application, before splitting each component out into its own service. This makes testing basic functionality much easier.
Currently the repo contains a thrown together crawler implementation and a basic console application, which vomits copious amounts of logging, for testing purposes, without doing much of actual use.
Design
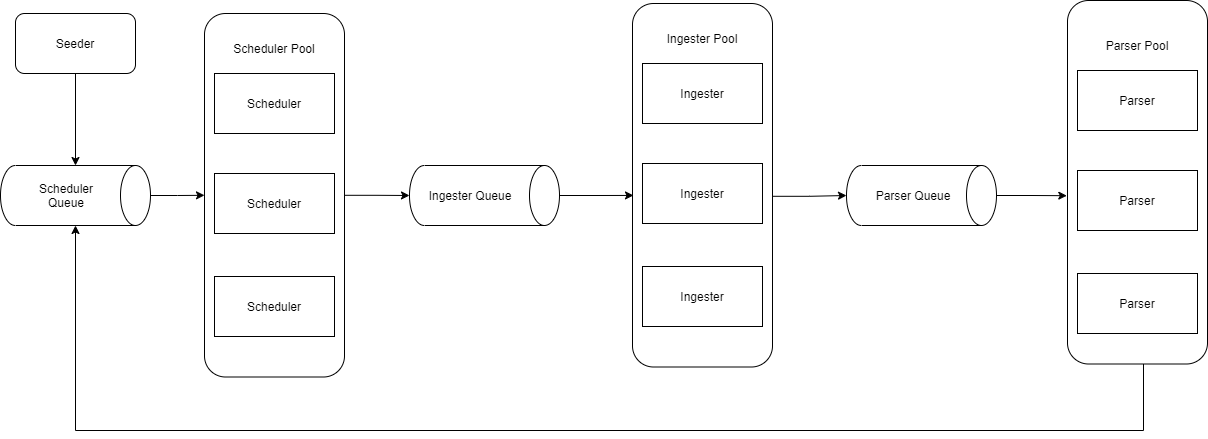
The crawler design is split into 3 main components, whose responsibilities are the following:
- The Scheduler is responsible for deciding if and when a given URL should be crawled
- the Ingester is responsible for downloading content for a given URL
- The Parser is responsible for parsing links from content retrieved by the ingester and passing valid links back to the scheduler
Each of these components receives work items from a queue and posts its results to the queue of another component when done. Although everything runs in a single application currently, the idea is to run each component as its own service and have multiple instances of each service running on different machines.
Basic architecture diagram
Features currently implemented
- Crawls multiple domains in parallel
- Limits the speed it crawls pages from the same domain
- Respects
Allow, Disallow and CrawlDelay directives in robots.txt
- Can pause and resume crawling
Next steps
- Create a basic Web API for controlling the crawler
- Output crawl results to some sort of database
- Figure out the best software to use for message queueing (currently looking at RabbitMQ)
- Implement more limits on what the can be download (eg: File type / size limits)
FYI: I have 6000+ blocked IP addresses and 250+ blocked IP ranges that say this is not a good idea
( no need to reply to this - I hearted your project btw, cos its a good learning exercise )
Progress update - 21st November
I’ve made a fair amount of progress since my last post. The majority of the time I’ve spent on the project has gone into getting RabbitMQ working as a queueing backend, so that the individual components can communicate with each other when they are running as separate processes
Rather than splitting each component out into it’s own API project I decided to create a more generic Component API, which can be configured to perform the role of any component (or multiple components.)
I’ve also created a management API, which is used to send commands to all active components. As of now I’ve only implemented pause/resume functionality, but I intend to expand this to retrieve useful information and listen for events from each component.
Currently the individual components and management API are set up as separate containers using Docker Compose. I intend to move to Kubernetes for container orchestration eventually, but at the moment I am still running everything on a single machine for testing purposes.
In terms of scalability, there is currently a limitation that only one instance of the Scheduler can be run at a time, as it currently holds all of it’s state in memory. I’m currently looking at using Redis to store this temporary state information, so that it can be shared between multiple scheduler instances.
Other features implemented
-
IncludeDomains and ExcludeDomains parameters can be used to limit which domains get crawled. Supports the use of wildcards (e.g: *.example.com => all subdomains of example.com)
-
The default crawl delay is now applied across an entire domain, rather than each subdomain of a given site. Turns out a lot of sites have huge amounts of subdomains, which are obviously processed by the same server (sorry Wikipedia!)
-
A MaxContentLengthBytes parameter, to prevent accidentally downloading huge files.
Next steps
-
Use Redis (or some other shared cache) to share state between multiple instances of the scheduler
-
Store output in some sort of database (if nothing else this would be useful for being able to resume crawling after restarting the crawler)
-
A basic frontend for the management API. Hopefully once I get this done I’ll be able to show some sort of demo  .
.
Progress update - 19th December
I’ve not has as much time to work on the project as I would have liked over the past few weeks but I have made significant progress on a variety of issues.
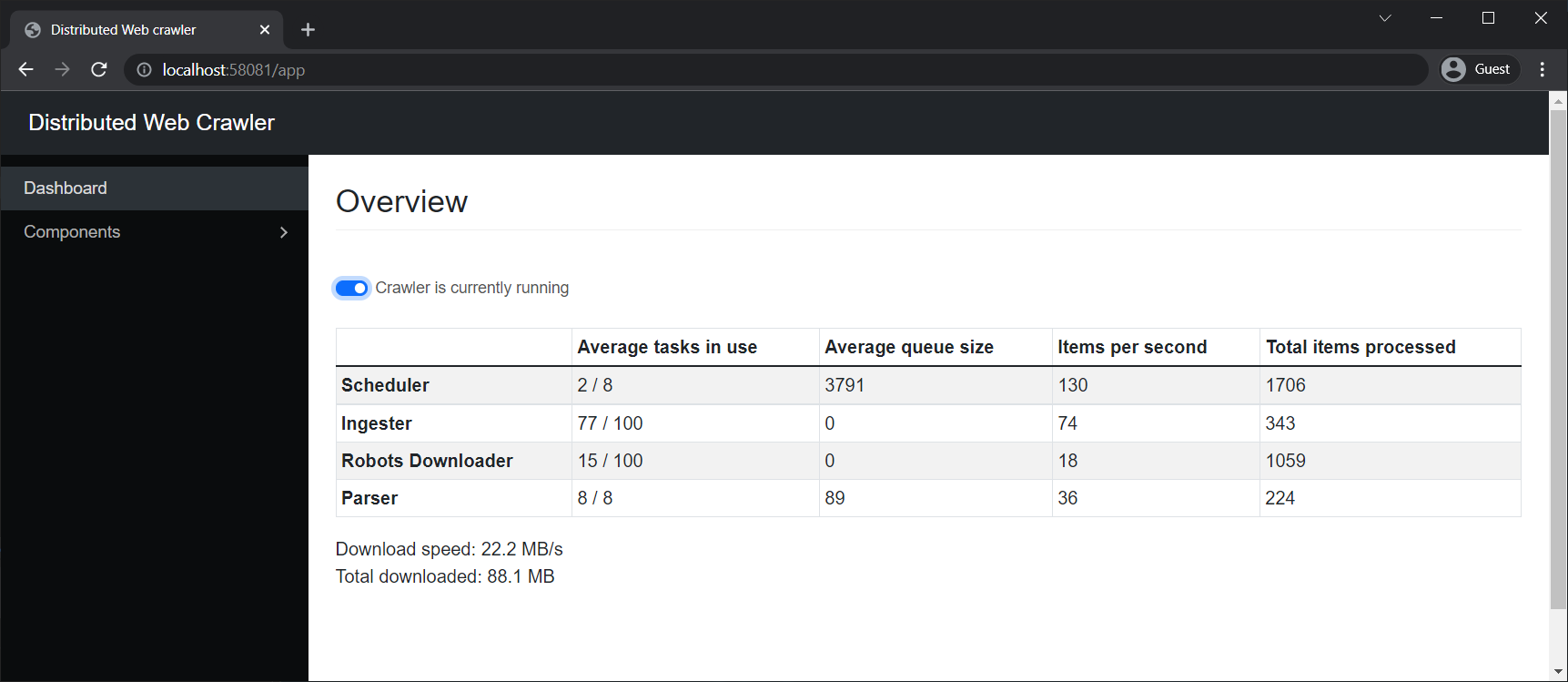
There is now a basic frontend to the management API written in React, which can be used to pause and resume the crawler. It also shows a summary of activity for each component, which are pushed to the browser from the management API using SignalR.
I also split the downloading of robots.txt files into a separate component. This increases overall throughput significantly, as the scheduler no longer has to wait for anything to download before it can schedule more URLs to crawl.
Other features implemented
-
Added QueueItemTimeoutSeconds, ConnectTimeoutSeconds, ResponseDrainTimeoutSeconds and RequestTimeoutSeconds timeout parameters to the configuration. These timeouts stop the ingester stalling for too long when given an unresponsive site.
-
Added IncludeMediaTypes and ExcludeMediaTypes parameters to prevent downloading certain media types.
Next steps
Unfortunately I haven’t had time to do some of the other things that I previously mentioned, like outputting results to a database, or Kubernetes orchestration. To be honest I didn’t expect that getting the tooling set up for the frontend and getting my head around react would take as long as it did.
I do plan on sticking with the project after the new year though. So I may post more updates if and when I make significant progress.
good idea, as long as the url is not part of that next proceess until the robots.txt for that url is processed. BTW if this data is intended to be browsable, it should still be fine to pull the index of the same url as well.
Oh the joys of web design and developement 
BTW if you are using React, you might want to consider Preact which is a lightweight dropin replacement.
Please do, and yeah, keep us up to date.
FWIW years ago I used to keep an archive server of browsable urls for offline use. It would have been useful to have the url’s pulled from nodes present in a more localized location, and it would have meant I could update them all at once instead of one at a time.
If you were to use SQLite (or some other file based record) for at least each nodes last crawled url, you could the export that to another node to assist with restarts. A filesystem based cache would sidestep (mostly) any issue with shedule service being down (because the data has not disappeared from memory).
Like I said in my previous reply I have a bunch of physical evidence that says (overall) this is not a good idea. But I am a developer and a perveyor of all things web, so I already know the amount of knowledge and experience you are gaining from doing a project like this. You never know, you might end up with a job at Archive.Org one day