Hi, Sorry if this post is not in the correct category. Please inform me if so...
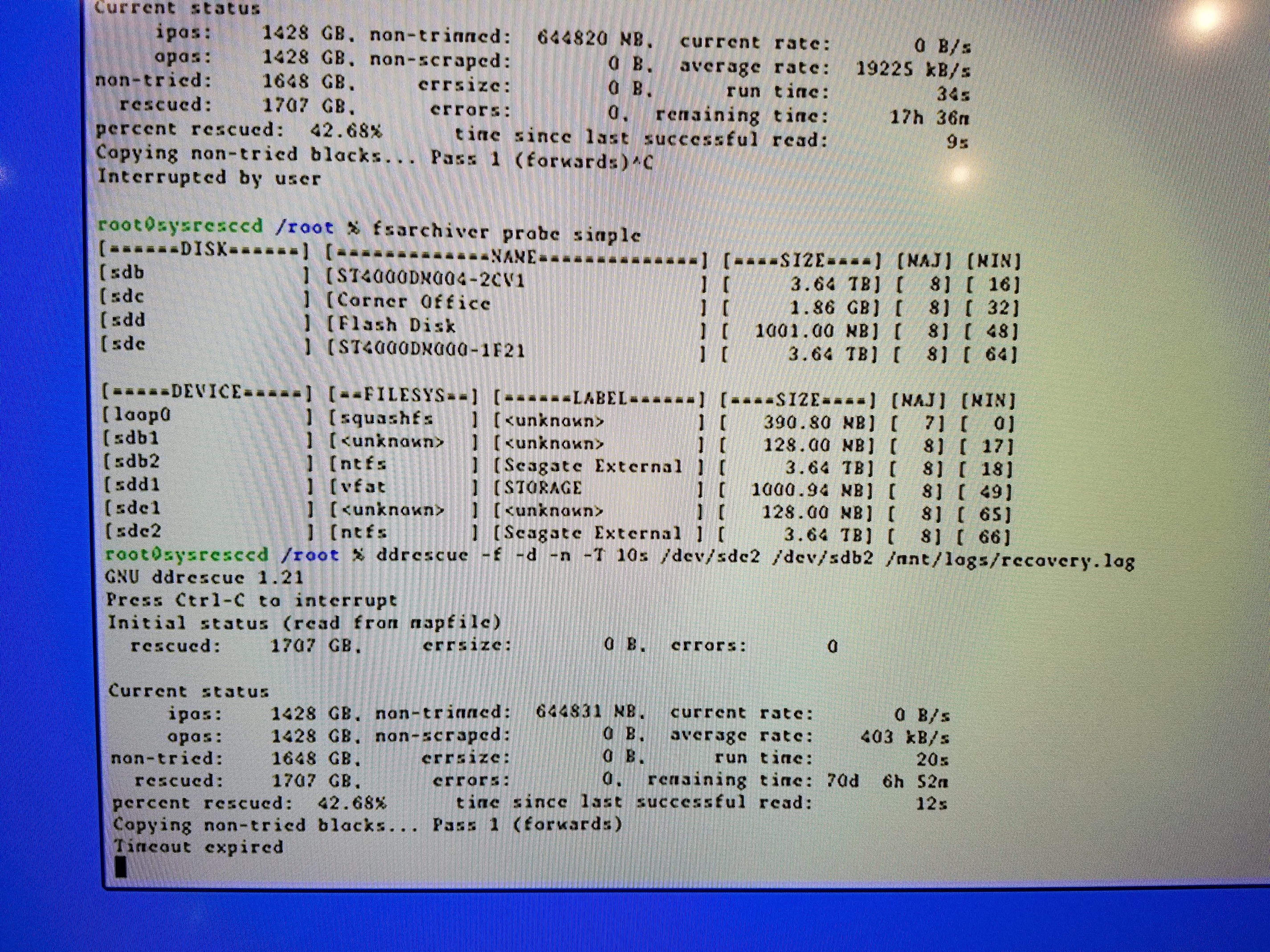
I am currently attempting to rescue the data on a large volume HDD that hit the floor while running. I have had some success after a head stack swap and I am currently at approx. 39% of about 3 TB data recovered using DDrescue. The issue I am currently facing is that the current rate starts out decent, but then within a minute or so drops to 0. The time since last successful read starts climbing along with the ipos, opos, and not-trimmed.
The only way to get it going again is the power cycle the source drive and restart ddrescue. This would take ages to complete and I would have to sit here the entire time.
I am at 1567 GB rescued. I have tried different triggers, including, -f -n -R -d.
If there is anything else I can try, please let me know. This drive contains many of my family photos and videos, and I hadn't gotten around to backing them up yet. Lesson learned...
I'm no rescue expert, but I wanted to warn you about the physical damage to the heads/platters that could have happen to your HDD:
Always with attempt to rescue HDDs (precisely with spinning disks and heads) there is a caveat that if it is (and in your case it is most likely) mechanical damage, any attempt of reading the data might actually destroy the platters and/or heads even further.
Any particles that most likely had been created during the impact could obstruct normal head movement, by getting between head and platter and potentially destroying both (secondary damage progression). Since it is spinning disk and moving head more particles are being created, thus making the damage cycle repeatable at higher rate (mostly to the platters and that makes more sectors unrecoverable).
No rescue program can overcome above fact. As this is not just matter of skipping the no longer readable sectors but those particles in the disk chamber.
The proper way is to open disk in clean conditions (but that is not something you do at home) and get rid of possible particles and then safely use any rescue software. When heads are damaged they need to be replaced, otherwise they simply can create scratches on the platter.
Now what are your options:
STOP
This first step is the most important. As in most cases a electronic component that is disconnected and not moved do not get additional damage. Get you self a time to weight options, and also prices of professional services.
In case you already done that, and you still want to go further: I do not know DDrescue options and possibilities beyond what I just read about it (briefly), I recommend skipping the next 10% of the disk and continue further with gap, then maybe go back to that gap (not sure if that is possible with DDRescue).
Hi, Thank you for your reply. I guess I should have made it more evident in the OP, but yes the head stack has already been replaced in clean room conditions. The head stack swap seems to be successful after recovering about 1.5 TB of data already.
Currently I'm just experiencing these drive stalls. I can get it reading again by power cycling the drive and recover a few more GB for an arbitrary length of time, then it stalls again.
What I'm mainly looking for on this forum is advice on what triggers/methods to use on the software side of things (ddrescue).
How do I tell the recovery to start a specific sector to skip a gap. I was looking at the recovery log file and I can't make sense of the current position. I believe the trigger will be -i then the position you desire, but I'm unsure.
And now I will make probably another mistake (I never used ddrescue, and you probably already looked into its possibilities).
I found this:
This post mentions about occasional need for editing the log. I assume that this is one way to influence the software behavior (e.g. mark larger range as bad/problematic sector so ddrescue will move on further than usually).
But If each time of the power cycle you get few more GB then I think you simply need to be patient.
In general SATA drives are the worst to handle error reads. The firmware can be stupid to the level of infinite loop while trying to read (while SAS firmwares are require to report error within specified amount of time).
Bump…still working on this…Are there any other commands that anyone can recommend when encountering these stalls? Should I change the sector size with -c?
Try setting the I/O queue depth to 1 with the following command before starting DDrescue. It will limit the number of sectors transfered in a single I/O to one, which can improve reliability on a failing drive.
echo 1 > /sys/block/sdX/device/queue_depth
Replace sdX with the actual device name. (The default queue depth is usually 31.)
What make/model of drive is it? On some drives you can change retry and timeout parameters which may help with recovery. Finally, check the drive manufacturers website for any firmware updates.
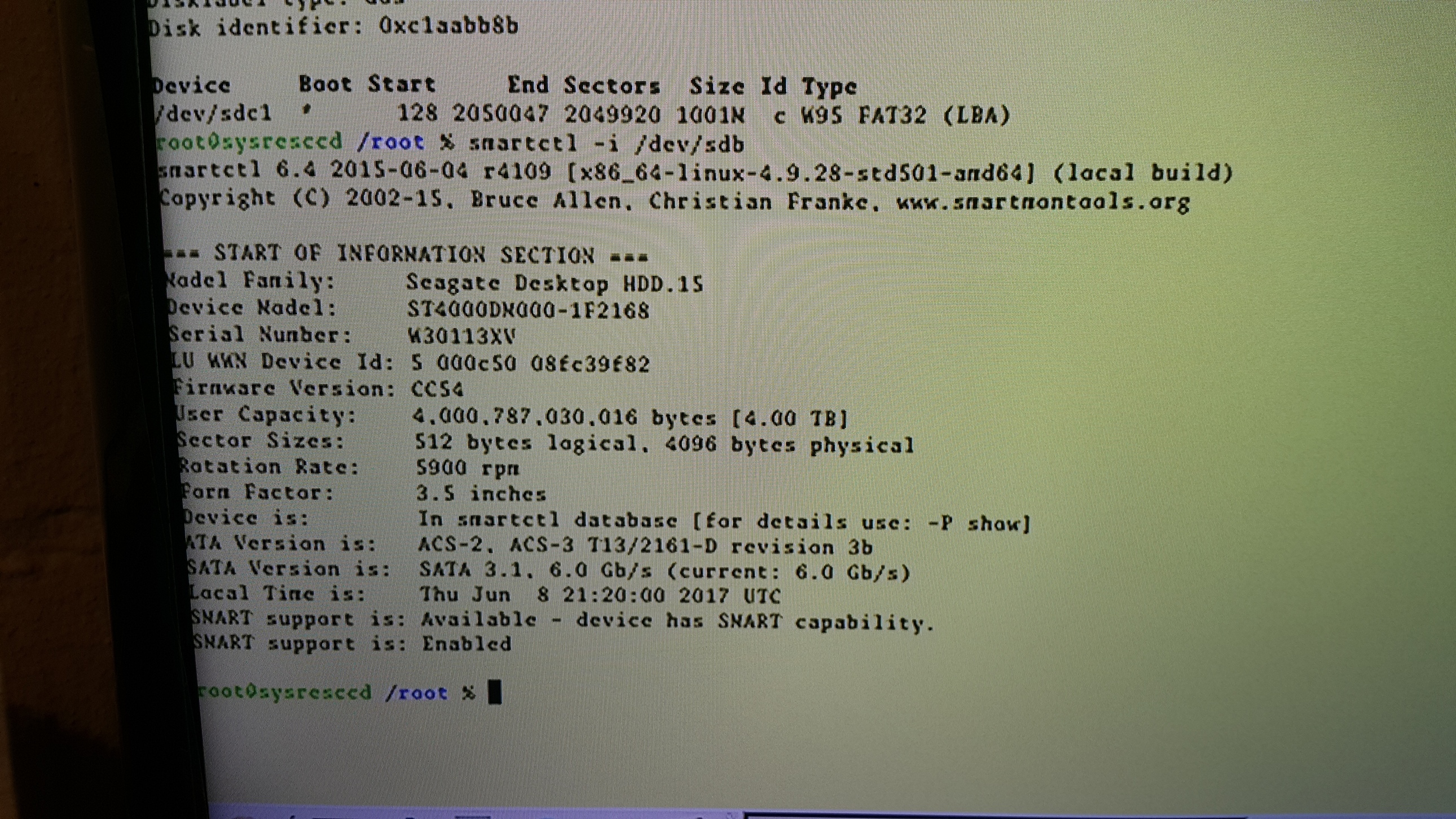
Thank you for responding. I will give that a try. This is a 4TB drive removed from a Seagate Expansion external enclosure. See picture for drive info. Will your recommendation work on System Rescue CD? I’m not running full Linux atm.
Its just so odd how it behaves. It will be reading then it cuts out and there is nothing I can do short of power cycling the drive to get it to ever read anything else. Seems there is something logical in the drive that tells it to shut down.
Thank you for the explanation. I tried it and I’m not sure it improved anything, but never less, definitely worth trying. By chance do you know how to keep the device name from changing everytime I power cycle my source drive? It is originally assigned /Dev/sda, but nearly everytime I power cycle the drive it alternates between /Dev/sda and /Dev/sde. This just makes everything a little more tedious with issuing commands considering I have to power cycle the drive like every 30 seconds.
 (I never used ddrescue, and you probably already looked into its possibilities).
(I never used ddrescue, and you probably already looked into its possibilities).