It’s a great question. I’m only hoping to get you to dig deeper into the question and consider what you’re actually measuring with this test scenario. You could learn a great deal more by implementing a more real-world test case.
I’ll answer you with an early quote:
Of course I’m interested in digging deeper, I’m sort of a computer nerd, I’m fascinated by it all.
I was making tests with a prime number generator and all runtime environments were the same results, then a colleague of mine suggested fibonacci, then I gathered a few info and made a demanding fib calculator.
I’m a noob in CS in general, know very little. But will continue with my own personal tests, and if something interesting pops up I’ll post here too.
I’m already working on a couple of algorythms to create a function that creates a 64 piece string and sort it a couple hundread times. I like thinking about the methods and such without researching pre-existing ones, that’s why this implementation is “bad code”… it’s just my code, you know, the only syntax I ressearched was for measuring time, which I hadn’t used before, and some commands in C++ cause I was a virgin with it.
This is just the beginning.
Just a suggestion for further investigation if you’re interested in taking the analysis further and learning new things.
It’s not bad because it’s yours, you didn’t invent this algorithm. It’s well known that this is a bad algorithm for computing Fibonacci.
Computer science isn’t about coming up with novel new algorithms. There is a wealth of existing algorithms that we leverage, and understanding their complexity with regard to time and space is one of the basic foundations of a computer science education.
So to be clear, I’m only hoping to show you a direction forward, not to ridicule you for being at the start of the path.
3 Likes
Dont let anyone drag you down.

6 Likes
I thank you for that.
And will dig deeper and figure out some real world applications, perhaps registry operations with database linking would be interesting. soon enough we’ll see.
2 Likes
Finite element analysis?
2 Likes
I dont know tbh.
Make me merging algorithms, because I need one to merge playlists for the pet project I started in devember last year… xD
Aka, do my ‘work’ for me…
I did not intend to argue. I’m just amused at another thread about “This language/distro/comic character is better than yours”
1 Like
My programming language brings all the boys to the yard, and I’m like: it’s better than yours.
4 Likes
Hearing that song as someone still in Elementary was weird, since the entire innuendo went straight over my head, since the song fell out of popularity quite quickly, I didn’t get the reference till high school when people started memeing it again.
3 Likes
So a good algorithm to test memory and pointer usage would be to make a B-tree sorter or something like that.
So say you compute the Fib sequence, then take each result and place it into the B-tree at random. Then You sort it in ascending order. Then sort into descending order.
This will cover how the stack/heap works, how memory pointers are handled, and how memory is managed. What you will find is that for single execution, Java would be slower and probably consume more memory for the same program. If you have it run through multiple iterations, you may find that once the memory footprint has plateaued, you will find that Java should speed up as the JVM will “warm” up and stop trying to acquire RAM.
That would be a more real world use case in regards to exercising the languages and their features.
1 Like
I was thinking something with text and input and output would be closer to a real world use case.
1 Like
Hold my beer, single-thread PowerShell 5 with the same implementation.
$startDTM = (Get-Date)
function fibonacci {
param(
[Parameter(Mandatory=$true, Position=0)]
[long]$x
)
if($x -eq 0){
return 0
}elseif($x -eq 1){
return 1
}else{
return (fibonacci($x-1)) + (fibonacci ($x-2))
}
}
$i = 0
while($i -le 50){
fibonacci($i)
$i++
}
$endDTM = (Get-Date)
$elapsedTimeSeconds = ($endDTM-$startDTM).TotalSeconds
$elapsedTimeMinutes = $elapsedTimeSeconds | Out-String
$elapsedTimeMinutes /= 60
$elapsedTimeMinutes = [Math]::Round($elapsedTimeMinutes,2)
"Time taken $elapsedTimeMinutes minutes ($elapsedTimeSeconds seconds)"
I gave up at 63245986…
(15 hours and 19 minutes)

I re-did it stealing some other implementation from StackOverflow:
![]()
3 Likes
Fair enough. I was trying to address the compute goal while having it exercise more than one aspect of each language in one execution.
Bruh. Were you running Powershell on a 133Mhz Pentium 1? that seems impossibly slow
1 Like
i7-3770k, single thread performance using the original function 
Edit; no lie:

Edit2; using this function:

3 Likes
You would have probably been dissapointed if you had stuck it out to compute values higher than fib(93). Assuming long is 64 bits on your system, the max value a signed, 64 bit number can hold is 2^63 - 1 (9223372036854775807) or, in other words, less than 94 number in the sequence.
If you used an unsigned long, your fib function could calculate the 94th number:
A naive cpp implementation:
#include <iostream>
#include <iomanip>
#include <memory>
int main(int argc, char * argv[]) {
if( argc < 2 ) { std::cout << "usage: fib (upper limit)\n"; return 2; }
unsigned long cFib = atol(argv[1]);
std::unique_ptr<unsigned long> p_values{new unsigned long [cFib]{0}};
if( !p_values ) { std::cout << "mem allocation error\n"; return 2; }
for( unsigned long index = 0; index < cFib; ++index ) {
switch(index) {
case 0:
std::cout << std::setw(2) << index << ": " << index << "\n";
break;
case 1:
std::cout << std::setw(2) << index << ": " << index << "\n";
*(p_values.get() + index) = 1;
break;
default: {
unsigned long temp = *(p_values.get() + index - 1) + *(p_values.get() + index - 2);
*(p_values.get() + index) = temp;
std::cout << std::setw(2) << index << ": " << temp << "\n";
break;}
}
}
std::cout << std::endl;
return 0;
}
but it would still overflow on the 95th number:
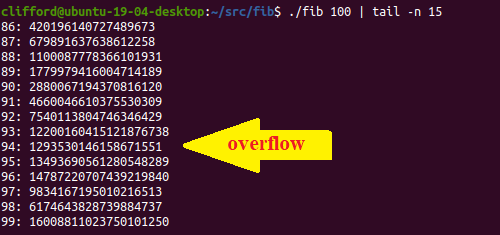
fib(95) through fib(100000) would have been overflowed gibberish without more bits.
2 Likes
Anyone care to adapt the code to use GMP in C and BigInteger in Java?
Have fun learning how to link libraries in C if you haven’t done that.
Because fibonacci is just the addition of two numbers, you can “cheat” your way to 128 bit by just using two 64 bit types and accounting for the overflow in a custom addition function:
barebones 128 bit addition:
struct _octoword {
using _dt = unsigned long;
_dt m_lower;
_dt m_upper;
_octoword(_dt lower = 0, _dt upper = 0) :
m_lower{lower}, m_upper{upper} { }
_octoword operator+(const _octoword& rhs) const {
_octoword temp;
temp.m_lower = m_lower + rhs.m_lower;
temp.m_upper = m_upper + rhs.m_upper + (temp.m_lower < m_lower ? 1 : 0);
return temp;
}
};
I think cpp is more convenient so your can hook the addition operator and the stringstream and string class saves a lot of bolierplate headache, but the c version would be similar.
The non-trivial part is displaying the 128 bit number in decimal. There is probably a more elegant way to do it, but you can break it down into four 32 bit parts (32 bits because the largest native type with division is 64 bit and you have to shift a 32 bit value left by 32 bits) and perform long division like we all did in grade school.
Add the display and a convenience ostream << hook to the class:
std::string _128bit_to_dec_str() const {
const unsigned int radix = 10;
std::stringstream ss;
unsigned int chunk32[4];
chunk32[0] = m_upper >> 32;
chunk32[1] = m_upper;
chunk32[2] = m_lower >> 32;
chunk32[3] = m_lower;
do {
_dt remainder = chunk32[0];
_dt divisor;
for(int index = 0; index < 4; ++index) {
divisor = remainder / radix;
remainder = ((remainder - divisor * radix) << (index < 3 ? 32 : 0)) +
(index < 3 ? chunk32[index + 1] : 0);
chunk32[index] = divisor;
}
ss << (unsigned int) remainder;
} while( chunk32[0] != chunk32[1] != chunk32[2] != chunk32[3] != 0 );
std::string str{ss.str()};
std::reverse(std::begin(str), std::end(str));
return str;
}
friend std::ostream& operator<<(std::ostream& os, const _octoword& rhs) {
if( rhs.m_upper == 0 ) return os << rhs.m_lower;
return os << rhs._128bit_to_dec_str();
}
And then just modify the original to use the 128 bit struct instead of an unsigned long:
Complete 128 bit fib:
struct _octoword {
using _dt = unsigned long;
_dt m_lower;
_dt m_upper;
_octoword(_dt lower = 0, _dt upper = 0) :
m_lower{lower}, m_upper{upper} { }
_octoword operator+(const _octoword& rhs) const {
_octoword temp;
temp.m_lower = m_lower + rhs.m_lower;
temp.m_upper = m_upper + rhs.m_upper + (temp.m_lower < m_lower ? 1 : 0);
return temp;
}
std::string _128bit_to_dec_str() const {
const unsigned int radix = 10;
std::stringstream ss;
unsigned int chunk32[4];
chunk32[0] = m_upper >> 32;
chunk32[1] = m_upper;
chunk32[2] = m_lower >> 32;
chunk32[3] = m_lower;
do {
_dt remainder = chunk32[0];
_dt divisor;
for(int index = 0; index < 4; ++index) {
divisor = remainder / radix;
remainder = ((remainder - divisor * radix) << (index < 3 ? 32 : 0)) +
(index < 3 ? chunk32[index + 1] : 0);
chunk32[index] = divisor;
}
ss << (unsigned int) remainder;
} while( chunk32[0] != chunk32[1] != chunk32[2] != chunk32[3] != 0 );
std::string str{ss.str()};
std::reverse(std::begin(str), std::end(str));
return str;
}
friend std::ostream& operator<<(std::ostream& os, const _octoword& rhs) {
if( rhs.m_upper == 0 ) return os << rhs.m_lower;
return os << rhs._128bit_to_dec_str();
}
};
int main(int argc, char * argv[]) {
if( argc < 2 ) { std::cout << "usage: fib (upper limit)\n"; return 2; }
unsigned long cFib = atol(argv[1]);
auto p_values = (_octoword *) new _octoword[cFib]{{0}, {1}, {0}};
if( !p_values ) { std::cout << "mem allocation error\n"; return 2; }
for( unsigned long index = 0; index < cFib; ++index ) {
switch(index) {
default:
p_values[index] = p_values[index - 1] + p_values[index - 2];
case 0:
case 1:
std::cout << std::setw(2) << index << ": " << p_values[index] << "\n";
break;
}
}
std::cout << std::endl;
return 0;
}
The 94th element no longer overflows:
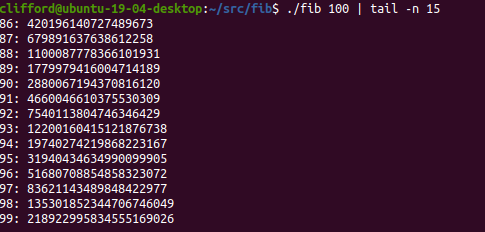
But 2^128 still doesn’t get close to enough space to fib(1000). Assuming I didn’t screw up, 128 bits overflows between fib(186) and fib(187):
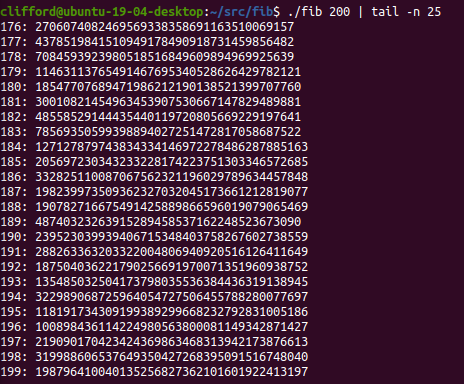
64 bits overflows on the 94th element, 128 bits overflows on the 188 element. That appears logical.
And of course you could slap together more space and go higher.
I’m no mathematician, but there can’t be that many people who need to display 128 bit+ numbers in complete decimal form. At that point surely scientific notation and rounding is acceptable for display.
1 Like
Multiple iterations using a bash script? Or just me running manually one after another? Would it need to be a complete project or just the class running on the command “java class enter”?
That is some long a$* time…
I’m lucky I didn’t go that route, if some gibberish didn’t show up at my screen I wouldn’t even know. But it would probably still be computed right? Just displayed wrong?
2 Likes
If your only limit was the precision of the type, then yes it would keep computing. But It would be like removing the hour hand from a clock. The minute hand would keep tracks of the minutes, but you wouldn’t know anything about the hour.
However the precision of the type is not your only limit. Because your fib function is recursive, with a high enough number (enough recursions), you will run out of stack space. The c implementation will throw an exception, which you haven’t caught, and the process will abort. I have no idea what java does when it runs out of stack space for a thread.
1 Like