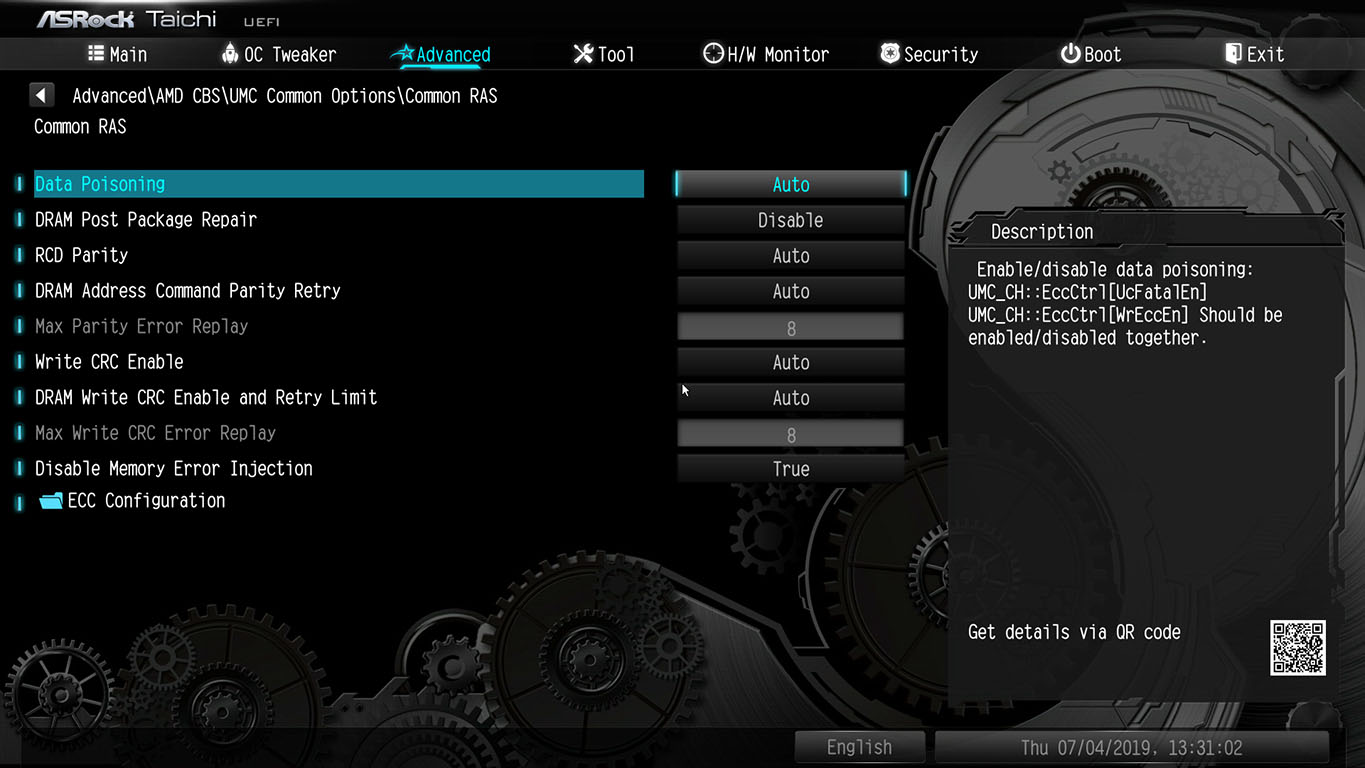
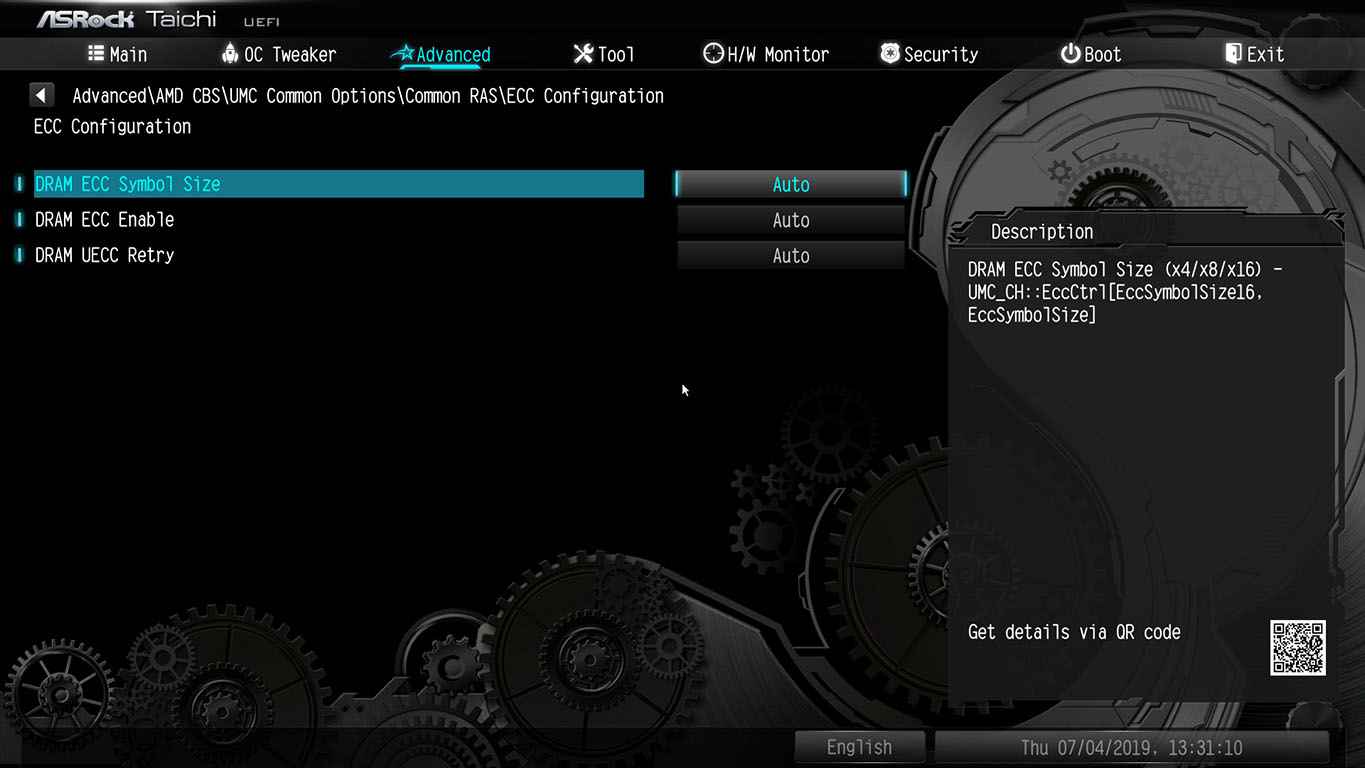
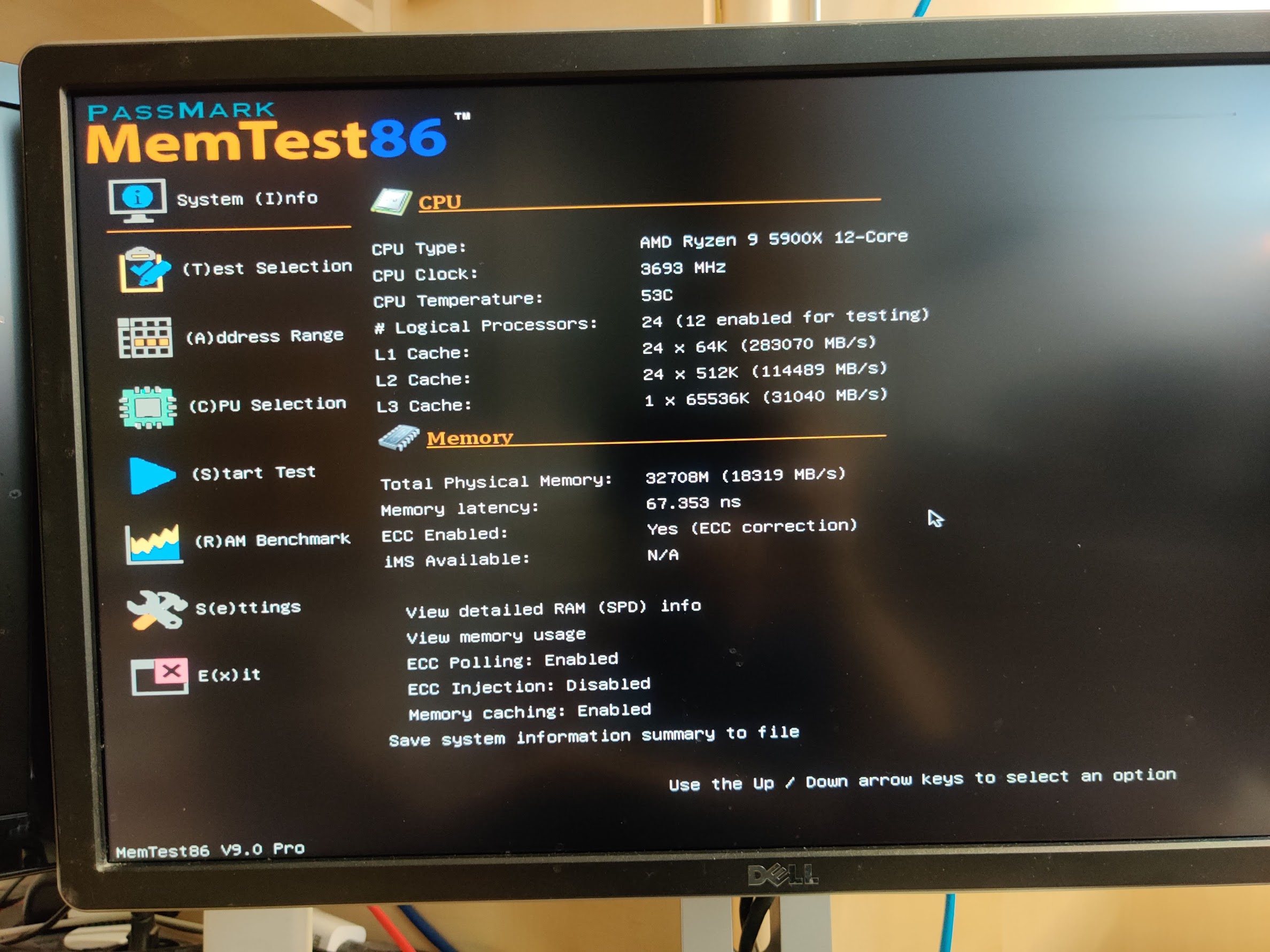
To resurrect this thread a little in a context of ECC error injection:
I also finally got myself those risers and soldered 2 wires to 4th and 5th pins which according to this docs represent Vss (ground) and DQ0 (data pin):
Shorting the wires/pins got me those edac errors:
[ 182.800367] mce: [Hardware Error]: Machine check events logged
[ 182.806350] [Hardware Error]: Deferred error, no action required.
[ 182.812647] [Hardware Error]: CPU:0 (17:8:2) MC16_STATUS[Over|-|MiscV|AddrV|-|-|SyndV|UECC|Deferred|-|-]: 0xdc2030000000011b
[ 182.824044] [Hardware Error]: Error Addr: 0x0000000122de4b80
[ 182.829804] [Hardware Error]: IPID: 0x0000009600150f00, Syndrome: 0x000036410b404002
[ 182.839057] [Hardware Error]: Unified Memory Controller Ext. Error Code: 0, DRAM ECC error.
[ 182.848933] EDAC MC0: 1 UE on mc#0csrow#2channel#1 (csrow:2 channel:1 page:0x255bc9 offset:0x780 grain:64)
[ 182.860114] [Hardware Error]: cache level: L3/GEN, tx: GEN, mem-tx: RD
[ 182.876950] mce: [Hardware Error]: Machine check events logged
[ 182.884294] [Hardware Error]: Deferred error, no action required.
[ 182.891937] [Hardware Error]: CPU:0 (17:8:2) MC16_STATUS[Over|-|MiscV|AddrV|-|-|SyndV|UECC|Deferred|-|-]: 0xdc2030000000011b
[ 182.904666] [Hardware Error]: Error Addr: 0x000000000edd8680
[ 182.911848] [Hardware Error]: IPID: 0x0000009600150f00, Syndrome: 0x000036410b404002
[ 182.921163] [Hardware Error]: Unified Memory Controller Ext. Error Code: 0, DRAM ECC error.
[ 182.931119] EDAC MC0: 1 UE on mc#0csrow#2channel#1 (csrow:2 channel:1 page:0x1dbb0 offset:0xc80 grain:64)
[ 182.942213] [Hardware Error]: cache level: L3/GEN, tx: GEN, mem-tx: RD
[ 182.950302] [Hardware Error]: Deferred error, no action required.
[ 182.957888] [Hardware Error]: CPU:0 (17:8:2) MC16_STATUS[Over|-|MiscV|AddrV|-|-|SyndV|UECC|Deferred|-|-]: 0xdc2030000000011b
[ 182.970694] [Hardware Error]: Error Addr: 0x0000000124286840
[ 182.977881] [Hardware Error]: IPID: 0x0000009600150f00, Syndrome: 0x000036410b404002
[ 182.987143] [Hardware Error]: Unified Memory Controller Ext. Error Code: 0, DRAM ECC error.
[ 182.997021] EDAC MC0: 1 UE on mc#0csrow#2channel#1 (csrow:2 channel:1 page:0x25850d offset:0x140 grain:64)
[ 183.008139] [Hardware Error]: cache level: L3/GEN, tx: GEN, mem-tx: RD
[ 183.025391] [Hardware Error]: Deferred error, no action required.
[ 183.032894] [Hardware Error]: CPU:0 (17:8:2) MC16_STATUS[Over|-|MiscV|AddrV|-|-|SyndV|UECC|Deferred|-|-]: 0xdc2030000000011b
[ 183.045615] [Hardware Error]: Error Addr: 0x000000002726fb40
[ 183.052715] [Hardware Error]: IPID: 0x0000009600150f00, Syndrome: 0x000036410b404002
[ 183.061932] [Hardware Error]: Unified Memory Controller Ext. Error Code: 0, DRAM ECC error.
[ 183.071734] EDAC MC0: 1 UE on mc#0csrow#2channel#1 (csrow:2 channel:1 page:0x4e4df offset:0x640 grain:64)
[ 183.082685] [Hardware Error]: cache level: L3/GEN, tx: GEN, mem-tx: RD
[ 183.090620] [Hardware Error]: Deferred error, no action required.
[ 183.098084] [Hardware Error]: CPU:0 (17:8:2) MC16_STATUS[Over|-|MiscV|AddrV|-|-|SyndV|UECC|Deferred|-|-]: 0xdc2030000000011b
[ 183.110746] [Hardware Error]: Error Addr: 0x000000013e967540
[ 183.117790] [Hardware Error]: IPID: 0x0000009600150f00, Syndrome: 0x000036410b404002
[ 183.126879] [Hardware Error]: Unified Memory Controller Ext. Error Code: 0, DRAM ECC error.
[ 183.136633] EDAC MC0: 1 UE on mc#0csrow#2channel#1 (csrow:2 channel:1 page:0x28d2ce offset:0xb40 grain:64)
[ 183.147617] [Hardware Error]: cache level: L3/GEN, tx: GEN, mem-tx: RD
[ 183.155459] [Hardware Error]: Deferred error, no action required.
[ 183.162858] [Hardware Error]: CPU:0 (17:8:2) MC16_STATUS[Over|-|MiscV|AddrV|-|-|SyndV|UECC|Deferred|-|-]: 0xdc2030000000011b
[ 183.175456] [Hardware Error]: Error Addr: 0x000000013e967540
[ 183.182474] [Hardware Error]: IPID: 0x0000009600150f00, Syndrome: 0x000036410b404002
[ 183.191547] [Hardware Error]: Unified Memory Controller Ext. Error Code: 0, DRAM ECC error.
[ 183.201061] EDAC MC0: 1 UE on mc#0csrow#2channel#1 (csrow:2 channel:1 page:0x28d2ce offset:0xb40 grain:64)
[ 183.211877] [Hardware Error]: cache level: L3/GEN, tx: GEN, mem-tx: RD
[ 183.219633] [Hardware Error]: Deferred error, no action required.
[ 183.226845] [Hardware Error]: CPU:0 (17:8:2) MC16_STATUS[Over|-|MiscV|AddrV|-|-|SyndV|UECC|Deferred|-|-]: 0xdc2030000000011b
[ 183.239196] [Hardware Error]: Error Addr: 0x0000000140f53980
[ 183.245987] [Hardware Error]: IPID: 0x0000009600150f00, Syndrome: 0x000036410b404002
[ 183.254886] [Hardware Error]: Unified Memory Controller Ext. Error Code: 0, DRAM ECC error.
[ 183.264477] EDAC MC0: 1 UE on mc#0csrow#2channel#1 (csrow:2 channel:1 page:0x291ea7 offset:0x380 grain:64)
[ 183.275340] [Hardware Error]: cache level: L3/GEN, tx: GEN, mem-tx: RD
[ 183.283031] [Hardware Error]: Deferred error, no action required.
[ 183.290292] [Hardware Error]: CPU:0 (17:8:2) MC16_STATUS[Over|-|MiscV|AddrV|-|-|SyndV|UECC|Deferred|-|-]: 0xdc2030000000011b
[ 183.302753] [Hardware Error]: Error Addr: 0x0000000141abca80
[ 183.309539] [Hardware Error]: IPID: 0x0000009600150f00, Syndrome: 0x000036410b404002
[ 183.318427] [Hardware Error]: Unified Memory Controller Ext. Error Code: 0, DRAM ECC error.
[ 183.328047] EDAC MC0: 1 UE on mc#0csrow#2channel#1 (csrow:2 channel:1 page:0x293579 offset:0x580 grain:64)
[ 183.338917] [Hardware Error]: cache level: L3/GEN, tx: GEN, mem-tx: RD
[ 183.757058] Disabling lock debugging due to kernel taint
[ 183.757323] [Hardware Error]: Deferred error, no action required.
[ 183.764110] mce: Uncorrected hardware memory error in user-access at 1b8b2d40
[ 183.770318] [Hardware Error]: CPU:0 (17:8:2) MC16_STATUS[Over|-|MiscV|AddrV|-|-|SyndV|UECC|Deferred|-|-]: 0xdc2030000000011b
[ 183.770327] [Hardware Error]: Error Addr: 0x000000000dc59640
[ 183.770329] [Hardware Error]: IPID: 0x0000009600150f00, Syndrome: 0x0000e0420b404002
[ 183.770330] [Hardware Error]: Unified Memory Controller Ext. Error Code: 0, DRAM ECC error.
[ 183.770347] EDAC MC0: 1 UE on mc#0csrow#2channel#1 (csrow:2 channel:1 page:0x1b8b2 offset:0xd40 grain:64)
[ 183.770350] [Hardware Error]: cache level: L3/GEN, tx: GEN, mem-tx: RD
[ 183.770354] [Hardware Error]: Uncorrected, software restartable error.
[ 183.770355] [Hardware Error]: CPU:3 (17:8:2) MC0_STATUS[-|UE|MiscV|AddrV|-|-|-|UECC|-|Poison|-]: 0xbc002800000c0135
[ 183.770360] [Hardware Error]: Error Addr: 0x000000001b8b2d40
[ 183.867228] [Hardware Error]: IPID: 0x000000b000000000
[ 183.873054] [Hardware Error]: Load Store Unit Ext. Error Code: 12, DC Data error type 1 and poison consumption.
[ 183.883818] [Hardware Error]: cache level: L1, tx: DATA, mem-tx: DRD
[ 183.891009] Memory failure: 0x1b8b2: Sending SIGBUS to memtester:507 due to hardware memory corruption
[ 183.901049] Memory failure: 0x1b8b2: recovery action for dirty LRU page: Recovered
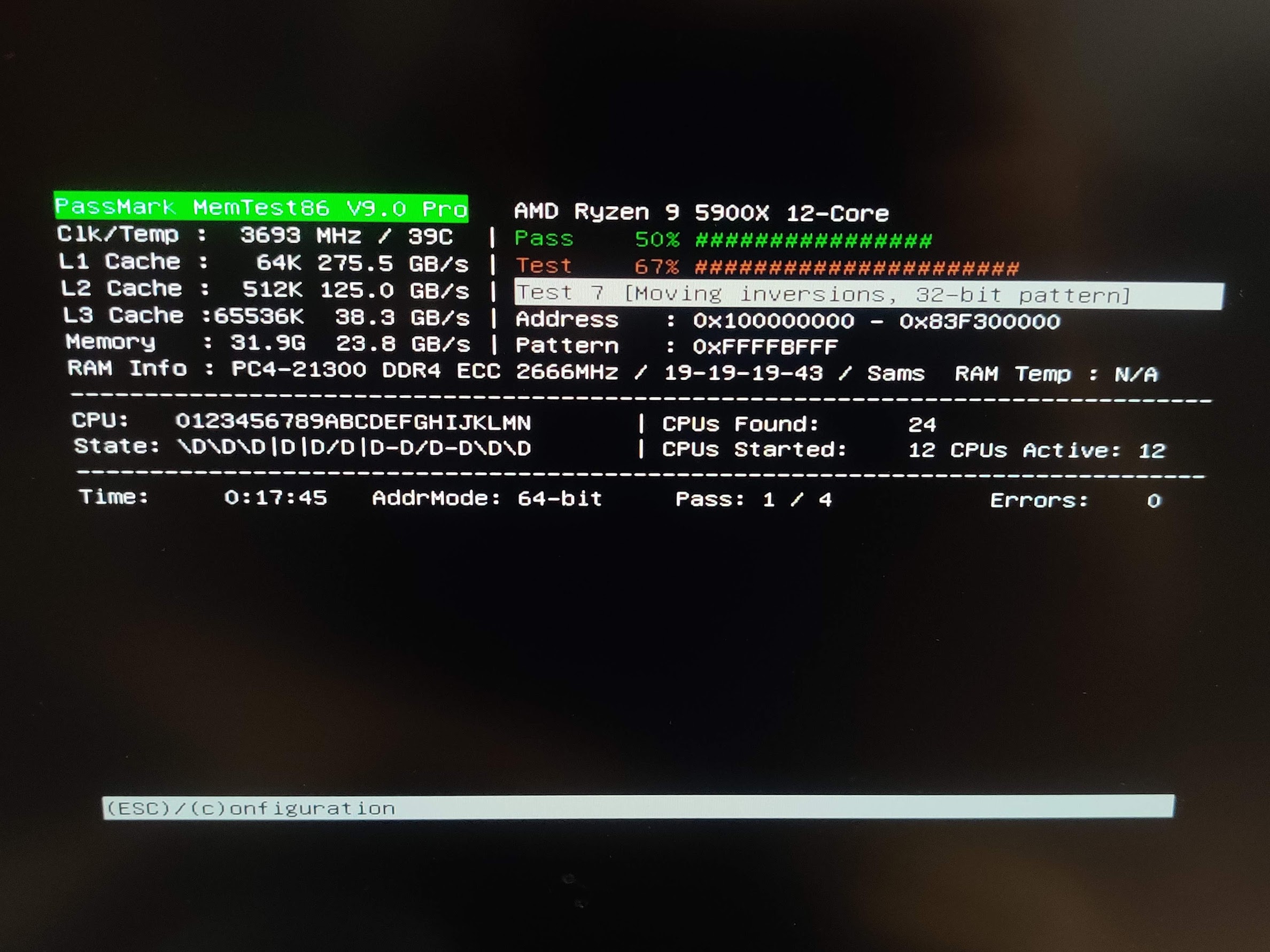
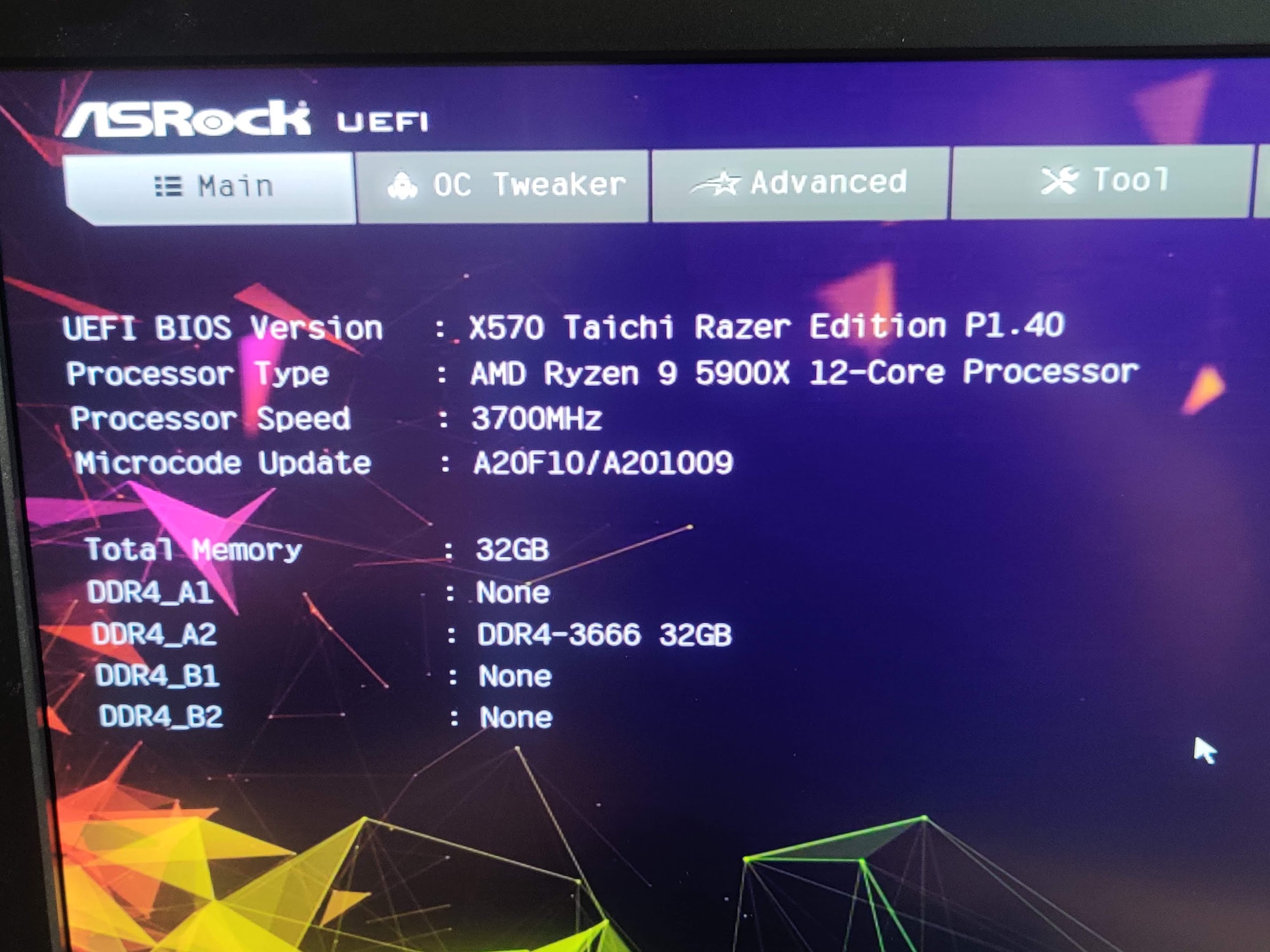
This was tested on X470D4U + Ryzen 2600
I plan to test various pins, resistor values, kernels, bios settings like PFEH, etc…
and make a separate thread with more details but for now: spending just a little time already gave me some interesting things to expand upon:
- too long wires prevented the board to post - I am fairly sure my soldering was good enough so I guess additional big antennas aren’t ideal.
- When testing older lts kernel (I think it was 5.4) I didn’t get edac logs. Instead I only got “Machine check events logged” in dmesg. Probably just too old edac driver but at that point Ryzen should have been supported already. weird - need to check
- Even though I shorted only one data pin It finally resulted in an uncorrected error - maybe there is a limit in a short period???
- I got “Deferred errors” but not “Corrected errors” that I normally see - also not sure why
- I confirmed that uncorrected error in userspace process results just in a SIGBUS signal being sent to it.



 .
.
