Hello everyone. I got this board yesterday to upgrade my Ryzen 7 1800X system to a proper server, and little did I know what I was in for. It has been incredibly frustrating.
Here is the hardware:
- ASRock X470D4U
- Ryzen 7 1800X
- RAM: 4x Kingston KSM26ED8/16ME (QVL - 2666 MHz) for a total of 64 GB
- PSU: Rosewill VALENS-500 (500W 80+ Gold)
The full parts list is here: https://pcpartpicker.com/list/gGR6vn
Problem 1
I was reusing the Noctua NH-U12S cooler, and had the same problem as others with the mounting hardware nearly touching the closest RAM module. I wrapped a bit of electrical tape around the CPU cooler mount to prevent any wacky electrical short-circuiting. Probably unnecessary, but better safe than sorry. If this RAM had heatspreaders, it wouldn’t have fit.
Problem 2
It immediately became apparent that this motherboard does not support XMP profiles, and the RAM defaulted to 1866 MHz. I balked at the enormous list of RAM timing fields which I don’t know the meanings of, so I booted into Windows and tried to use software (Thaiphoon Burner, etc) to read the XMP profile of the RAM so I could input appropriate information manually in the BIOS. No software was able to do this, thanks to the screwy motherboard.
I then updated the BMC to 1.60 and BIOS to 3.10 (both done through IPMI which is really handy), and in order to minimize update issues, I let it clear the configuration during these updates.
After the updates, Windows software was still unable to read XMP profiles. I ended up pulling out one UDIMM and inserting it into a different PC which was able to read the XMP profiles just fine. Here is the Thaiphoon Burner output for Kingston KSM26ED8/16ME:
Next, I converted these values to hex so I could input them properly into the BIOS:
(don’t waste your time putting these in)
I could not boot into Windows with the memory configured like that. Upon trying, it just crashed with no error report whatsoever.
Next, I tried leaving more of these settings on Auto:
(don’t waste your time putting these in either)
It still couldn’t boot into Windows.
Finally I decided to just set the Memory Clock Speed to 1333MHz and leave everything below set to defaults (Auto). This worked, and allowed me to boot into Windows.
HWINFO showed what I am guessing is the actual timings the motherboard went with:
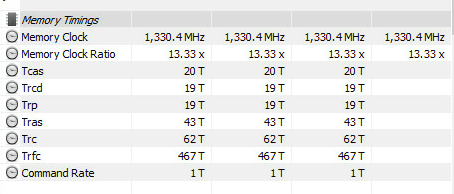
It is close enough that I just don’t care anymore. Interestingly, HWINFO didn’t have timing data for the 4th slot. I’ll chalk that up to the screwy motherboard again.
Problem 3
After BMC/BIOS updates, and getting the memory speed set and Windows bootable again, I tried using Handbrake to transcode a 2 hour H.264 1080p clip to H.264 (medium preset). It purred along fine achieving about 25 FPS transcode rate which is about what I’m used to seeing from this CPU. An hour in, Handbrake crashed.
I didn’t mention this earlier, but back before I updated the BMC/BIOS, I noticed Task Manager reported the CPU was running at 0.54 GHz, Memory at 1866 MHz, and CoreTemp reported the CPU temperature locked at 30°C (looking back, I think this may just be where it settles when CPU_PROCHOT is asserted).
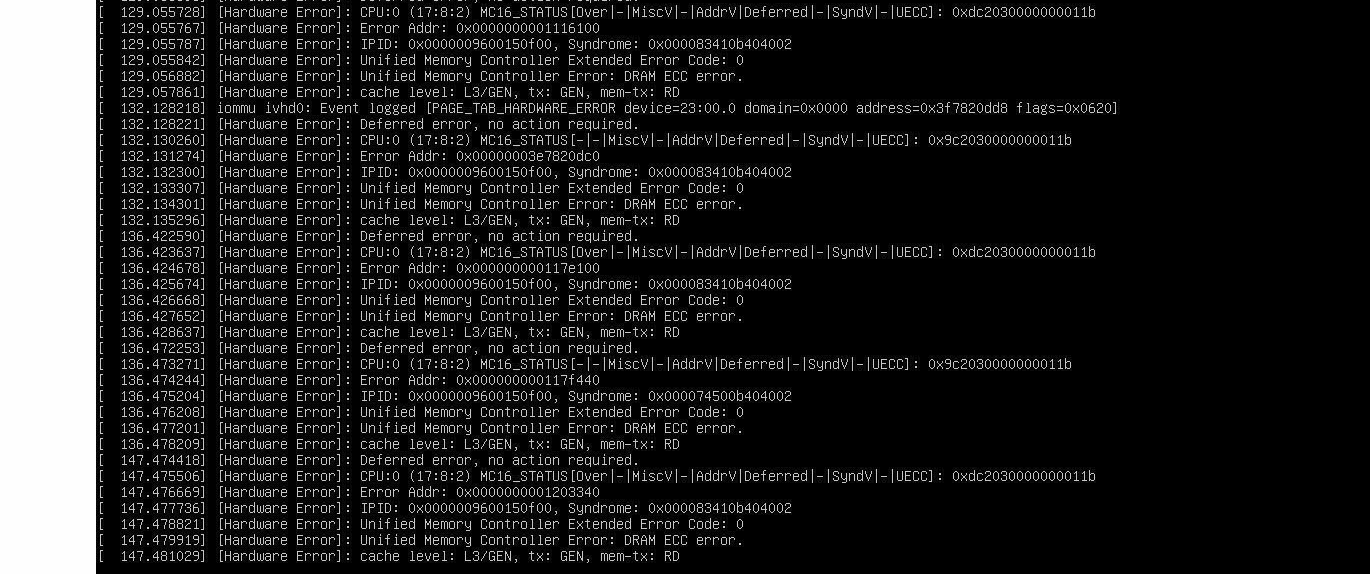
After BMC/BIOS updates, Task Manager showed CPU speed bouncing all around the normal range, but RAM speed was missing, and CoreTemp shows the correct CPU temperature (the same value which HWINFO reports as “tdie”). Interestingly, the IPMI web interface seems to get its CPU temperature from “tctl” which is consistently 20°C higher than “tdie”. While running Handbrake, the CPU temperature reached 70-74°C, which meant the board saw it as 90-94°C. Looking at my IPMI log, it was constantly logging temperature changes and CPU_PROCHOT would briefly become asserted before being deasserted seconds later. See full log here: https://pastebin.com/U3qmd1Px
All the while, CPU temperature was only low to mid 70s.
Unfortunately, I also have the bug where CPU_PROCHOT gets stuck enabled for no apparent reason. It happened before and after the BMC/BIOS update. As I type this, CPU_PROCHOT has State Asserted and Task Manager shows 0.54 GHz unwavering. But for at least an hour last night, it was fine and running normally, and I have no idea why.
Problem 4
After the Handbrake crash, I wanted to run MemTest86+. But at some point, all 12 IPMI virtual media devices appeared in the boot list and pushed the real USB devices out of the list. I even tried booting from a MemTest86+ ISO mounted through the KVM web interface. It didn’t work. I tried Ultimate Boot CD too. Didn’t work. MemTest86 from PassMark. Didn’t work. This had me chasing my tail for two hours before I tried turning off most of the virtual media devices. That got USB devices showing again, but I still couldn’t boot into MemTest86+ or Ultimate Boot CD or MemTest86 from PassMark. Finally I turned off CSM entirely, and this allowed MemTest86 from PassMark to boot (the only one of the three that supports UEFI). I let this run overnight and it only got through about 2 and a half passes, but no errors.
Problem 5
This morning, after closing MemTest86, I wanted to boot into unRAID, which was the whole purpose of this server build. So I did that, got signed in, and began writing this post. I looked back a bit later and the system had crashed. Nothing to indicate a problem in IPMI logs. KVM showed no signal. A physical monitor attached to the machine showed no signal. IPMI said it was still powered on. The motherboard’s POST code display was blinking 00 on and off, and I noticed 4 small red LEDs next to the fan headers blinking red (maybe due to CPU_PROCHOT?).
I rebooted and looked for logs, but IPMI still showed no evidence of what happened, and it turns out unRAID doesn’t persist its logs between boots.
Conclusion thus far
I just ran a CPU MARK test (in PassMark PerformanceTest 9.0) with the CPU_PROCHOT thing asserted and the clock speeds limited, and got a whopping 2833 score. Yippee.
So yeah, stability and huge performance problems on a system specifically designed for greater stability. ASRock had better fix this.

 I didn’t make any changes in the BIOS.
I didn’t make any changes in the BIOS.