I've written a regex for my colleague, I want to basically be able to filter through some strings.
Now here's what I need, I need the regex to start on the character '<' and end on the character '>'.
I need it to only find things that don't start with the letter after a certain string occurs T or V.
I have written an example but I've left it in work, I'll be sure to update this post tomorrow, but if anyone can think of a quick little regular expression which does that exactly, that would be great.
My colleague is writing a script to remove a tonne of data, and he's trying to write a regular expression for that. He's running the script on some XML file as far as I'm aware, hence why it has to look at each case, specifically where it starts with '<' and ends with '>'. The T and V part, I'm not 100% sure why that's essential, but he says it is, so there we go I guess? .. I think that has something to do with the actual data more so than anything else.
Another minor issue, ALL of the tags are inline, with no spaces, I found that made it a little more tricky earlier.
So here's the regex I tried:
/.+?(?=<blah="(T.*|V.*)*./g
I've now also tried something like:
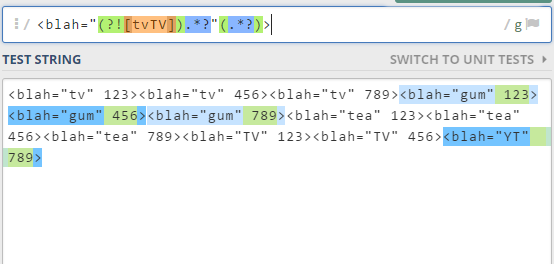
/<blah="(?![tvTV]).*?"(.*?)>/g
I can confirm that the second one appears to be working just fine. Take a look at the results:
I'm sure there's an easier way around the case sensitive thing than what I've done, but hey, it works.
Protip: make a backup of your file before doing any regex-fu on it:
I'm not sure I exactly understand number 2. I'd need you to be more clear about what number 2 means, however, I wrote this on my assumptions.
<[^TV]\w*>
Matches <HTML><BOLD> Doesn't match <TML><VHS>
That could get you started, but I'm not sure if it'll do everything you need it too. That seems to work in sed, but I'd need more info about what you're trying to do. Do you need access to each match, are you searching and replacing, which language are you using? Also, is there always a char before or after either of the "<" or ">" - is there always a space there. Please give me a little more to work with or a sample of the data. If you're worried about it being on the web feel free to pm it to me. I'd need to identify a pattern.
Do you need to match the closing XML tag as well? More information may be better here.
I just will point out that since it is actually XML being processed you should at lest look into XSLT (in which you should actually also be able to incorporate Regex - probably starting with XSLT2).
That's more complete than mine. I'm not exactly sure what the OP wants. I actually feel bad posting without knowing exactly because regex is really powerful and I don't want them to screw up their file.
What @jak_ub said could be the way to go if there are already tools built in XSLT for this. I'm not anyway confident with XML so I have nothing to input on it.
OP didn't give much info to go on anyway so at least they have something to go on now.
Don't worry about screwing up the file, we've got backups.
But we just want to remove any tags that doesn't start with < .... "T (OR) "V ... (AND obviously the tag ends with)>
I'd say the most annoying part is that it's all in line which makes running the regex function weirdly, hence why I'm trying to force the regex to end on >. If everything were on it's own line, it wouldn't be so bad, I wrote a regex which was able to function well enough provided each tag was on it's own line.
That's BASICALLY what the data looks like, and we were just trying to find data in blah that starts with T or V. Well we've solved it now anyways, thankfully, but I think you get an idea as to what the data looks like now?
And thank you for your help, not just with the regular expression, but for also trying to help me out when I was having brain damaging brain farts with that JS feature I was implementing. I'm happy to say I've solved ALL the problems I was having with that JS algorithm!
I know that this topic has been settled but I just love messing around with that regex webapp. I'm actually learning how to regex thanks to that webapp.
See my stupid and totally pointless example below.