I guess I cheated. 27 years of Computer system architecture, engineering and problem solving experience maybe gave me an unfair advantage ;-)
The CCX does have an observable performance degradation under heavy CPU+GPU load, The switching transport is reliant on the Data Fabric to switch between modules, If there is contention for usage of the DF, whatever needs to use it has to wait until a slot opens up to make use of the transport. CCX thread switches is just one of the many things using the DF that all have to wait for available slots if the Fabric is fully loaded. Even so the degradation from delays to switch a thread is still only in the 60-100 of nano seconds with each switch. Putting it in context, access times to an SSD is in the region of 100,000 nano seconds and access time to a spinning rust disk is about 8,000,000 nano seconds.
The problem that I have with almost everything related to Ryzen coverage (Wendell aside, who has reported his observations and reserved judgement so far) is the widespread suspension of rational, logical thought and the wholesale unthinking use of cookie cutter process. CCX thread switching/fast GPU only stresses CPU cores has been applied without much thought or understanding of what is actually being tested.
Here is another example of what I am talking about. The "Linux/Windows scheduler" issue that you mentioned.
We discovered that Geekbench multicore Linux benchmarks get better scores on Ryzen than the equivalent Windows geekbench scores. We hear "That's evidence of a windows scheduler problem on Ryzen!!!".
See these Ryzen results sorted by multicore scores.
https://browser.primatelabs.com/v4/cpu/search?dir=desc&q=ryzen&sort=multicore_score
But wait a bit.....
This took me 5 seconds to type 6900K in the search bar and hit enter and then sort by multicore scores.
https://browser.primatelabs.com/v4/cpu/search?dir=desc&q=6900k&sort=multicore_score
oops....
How the hell did something so easy to disprove get so much traction that it became a "fact" that was used as unquestioned evidence for a windows scheduler problem in Ryzen?
What is it about Ryzen that has turned almost everyone into Chicken Little? Or am I getting it wrong? My sore head and the Acorn on the ground really is proof that the sky is falling.
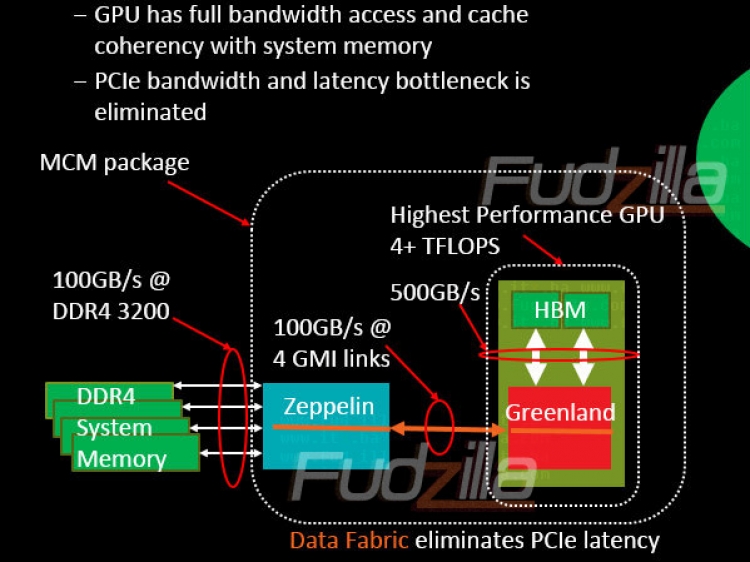
AMD communication on how Ryzen and the data fabric actually works and what the bandwidth potential is has certainly been incomplete, and even contradictory in some instances. Publishing the diagrams that only show partial elements in isolation are guaranteed to cause confusion as the vast majority of people looking at it cant piece the puzzle together for themselves and rely on the tech media "experts" to tell them. Maybe Jim Keller finished up this time and no-one bothered to ask him how the chip worked.
I suspect that the confusion of about the fabric comes from this article on Fudzilla in 2015
this diagram in particular that certainly doesn't match up with Ryzen