You seem confused on the comment of the large victim cache. Let me put it into perspective.
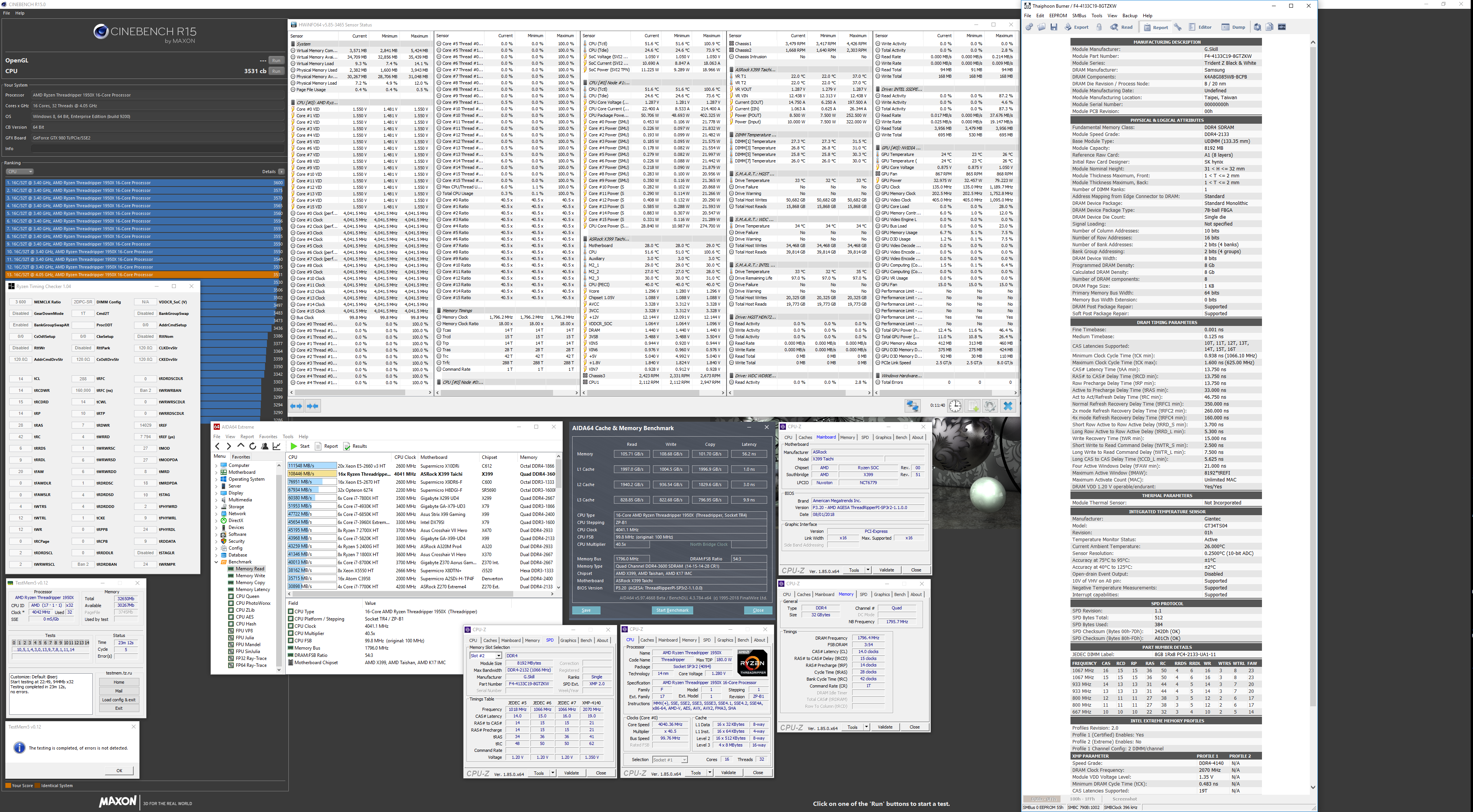
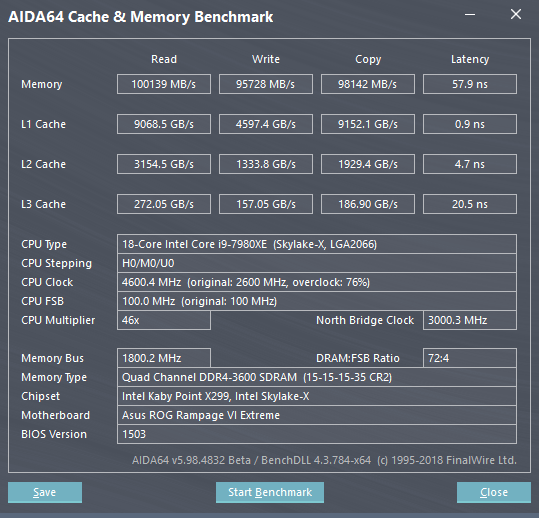
With AIDA64, measuring peak throughput, AMD’s L3 cache on TR is around 800GBps, while Intel’s L3 is around 200-300GBps. For overclocked ram on TR or Intel, you could see around 100GBps, and around 160GBps for Epyc.
So, AMD’s L3 has a peak around 3-4x that of Intel’s L3 cache speed, but the cache serves a different purpose: being a victim. That means it is a cache pool all cores will draw on and share, which means lots more calls, etc., so faster speeds help keep the data flowing as all cores can access it.
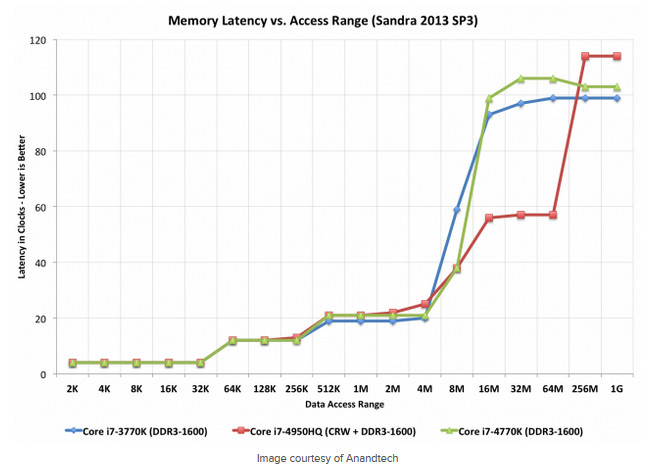
With the 32-core 2990WX, we saw that aside from the off die latency to get to the memory controller, there was more work keeping the cores fed using just 4-channel memory over the 8-channel Epyc chips.
So, what is the solution? Well, if you double the L3 cache per core to 4MB from 2MB, then double the cores with that, so long as you keep mem latency down and latency between dies and I/O chiplet down, then the faster L3 cache can serve up large amounts to the cores to keep them fed, combating the memory channel issues seen with the off-die access of the 2990WX. There is also the chance that speeds of the caches have been increased.
For example, the L2 caches between AMD and Intel solutions are roughly the same speeds, with slight edge on peak going to Intel. But, for L1 cache speeds, Intel is like double the speed of what is seen on AMD according to AIDA64, if not more. Some of that will be effected with AMD’s changes to the branch prediction, instruction pre-fetch, etc. So some other good changes to that were hinted at, while we will know more at launch, with some other hints coming before launch as well.
Does that make a little more sense on the larger cache size making up for not increasing the memory channels to a degree, which double the memory channels to double the memory bandwidth would still fall far short of the faster L3 cache speeds, and doubling the amount that can be held in that cache leaves it more on tap for the cores to call on.