Wow, perhaps they mixed up the listing of a “tray” CPU with “a tray of CPUs” 
Thanks for willing to test! I’m curious on what clock speeds to expect given a certain number of cores loaded. If on Windows, you could try this Sysinternals tool: CpuStres - Windows Sysinternals | Microsoft Docs
There you can start a bunch of processes, and set “Activity level = Maximum” in the menu. It is also possible to pin processes to specific cores. (did not work when I tried)
You could test e.g. to run 4, 8, 12 or 16 processes in parallel, and monitor the CPU frequency in task manager - I assume the number reported there will be the max frequency among all running cores.
What I’m not sure about is how SMT will be used in this scenario - if one thread / core is loaded first, then the above strategy will work - however if the scheduler opts to use both threads on a core before loading the next one, then we would need to double the numbers. I’ll investigate this on my Rome chip and get back… [the boldface scenario above is the correct one, see results below]
(I think for a “gaming VM” scenario it would make sense to load all cores on a CCD at the time, and test with 1, 2, 3, or 4 CCDs loaded. As a VM would probably run on 1-2 CCDs in order to share cache. It is possible to pin processes to cores within CpuStres, however it looks a bit cumbersome for 32 threads as it can seemingly only be done from the menu, one process at a time. It might be easier on Proxmox in the end.)
EDIT:
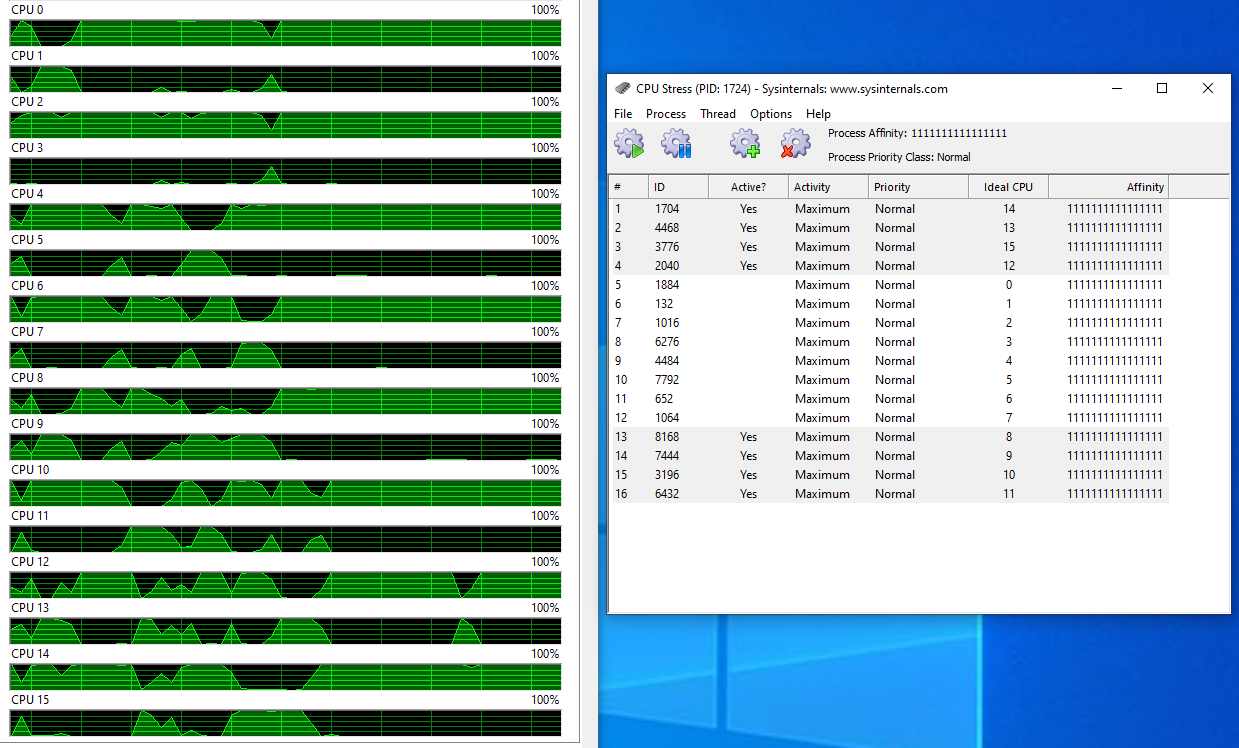
It looks like Win10 schedules one thread per socket first. Here is a screenshot from my 7252 (8c16t) when running CpuStres:
Summary
Every other logical CPU gets loaded, which corresponds to one thread per core (I checked the order with Coreinfo). Generally, it looks like Win10 spreads threads widely, utilizing all CCX when possible.
The “Affinity” and “Ideal CPU” columns seem buggy, I could not use them to control thread placement.
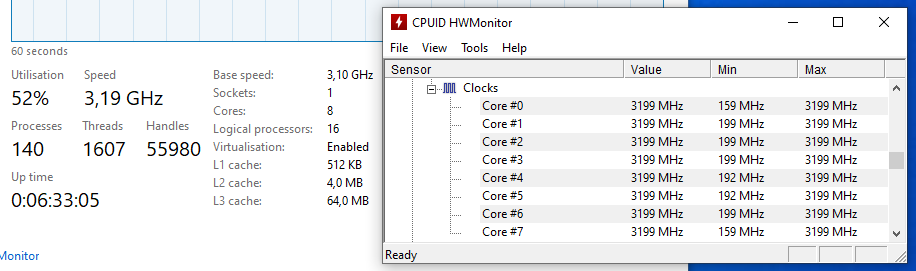
Forgot to include the clock reading in the picture above:
Summary
I believe that neither Rome nor Milan would leave one core at higher clock while clocking down the rest under load, why the single number from taskman.exe (on the left) would suffice. If unsure, one can check with CPUID HWMonitor (right).
Interestingly, my 7252 never goes below its max speed (3.2GHz) under this type of load. For prime95, however, it went down to base when fully loaded (probably due to AVX). And this is on the lowest cTDP setting
Testing of clock dynamics on Win10 (tentative procedure)
@MasterMace (provided you are still running Windows; or anyone else with a Milan chip running Windows): it would be interesting if you could try using CpuStres to start 4x “max activity” threads at a time up to 32, and note the max clock (as given by taskman.exe) at each step. E.g.:
Threads clock
4t ?
8t ?
...
32t ?
Preferably at max cTDP setting. What is interesting to see is how quickly max clock drops when more and more cores are loaded. NB: this result will not speak directly to the scenario when a CCD-pinned VM is running under load - for that we need to control core affinity too, which adds complexity.
Optional second test
Repeat the same procedure with Prime95 instead of CpuStres. Prime95 uses AVX and is therefore more power-hungry - I believe it will model more of a worst-case scenario.
Final remarks
The above could surely be scripted, but my savyness with cmd/powershell is limited… - I’ll try to come up with a procedure for *nix too, using a bit more automation.
Finally, I think the most interesting result would be at max cTDP setting. According to @wendell in another thread, Milan can boost quite a lot over rated base clock even under full load. I’d also curious if Milan ever gets significantly above rated max boost.