Does anyone with an H12 board know if you can disable the all-fans-to-max on power-on? I just measured 76dB on my sound meter - this SC747 case has some very serious fans for passively cooled GPUs!
Austria
So why is Europe in “preferred son” status and nobody in the U.S.?
I noticed that the fans went to max also immediately after I rebooted BMC (right after the power led stopped blinking) when the system was running. They stayed like that for not more than a minute. At that time, “ipmitool sensor” returned only blank values for all monitored variables.
I don’t know if it leads you closer to an answer to your question. But it seems that in this time window, no fan control whatsoever is available.
1 Like
I am looking at Gigabyte server boards for Epyc and I see this about ram - Max Memory Speed Even at 2 DPC
With GIGABYTE unique solution, maximum memory speed is now supported, even when using 2 DIMMS per channel*. GIGABYTE’s server platforms give you the performance edge, with more memory capacity at faster speeds.
* Enabled via BIOS setting (“UMC Common Options” “DDR4 Common Options” Configure “Enforce POR” setting). Please follow product QVL. Please consult your GIGABYTE sales or technical representative for more information.
is this the case also for AsRock - ROMED8-2T ?
I finally got around to investigate latency differences based on DIMM placement with my 7252. This is interesting because it is a “4-channel optimized” chip, where only half of the package (2 quadrants) is populated with CCDs. Will this have a consequence for the optimal DIMM placement, given that half of the (physical) memory channels connect to the far side of the IO die relative to the populated compute dies? Or, will there be no difference because there is only one NUMA node? (recall that NPS > 1 is not possible to set for these chips).
My testing suggests that there is a difference. I get significantly worse latencies with the 4 dimms in the ABEF configuration, compared to the CDGH configuration (as recommended by manual).
mlc results from CDGH
Intel(R) Memory Latency Checker - v3.9
Measuring idle latencies (in ns)...
Numa node
Numa node 0
0 117.8
Measuring Peak Injection Memory Bandwidths for the system
Bandwidths are in MB/sec (1 MB/sec = 1,000,000 Bytes/sec)
Using all the threads from each core if Hyper-threading is enabled
Using traffic with the following read-write ratios
ALL Reads : 63977.2
3:1 Reads-Writes : 61029.4
2:1 Reads-Writes : 61346.4
1:1 Reads-Writes : 64361.8
Stream-triad like: 64604.6
Measuring Memory Bandwidths between nodes within system
Bandwidths are in MB/sec (1 MB/sec = 1,000,000 Bytes/sec)
Using all the threads from each core if Hyper-threading is enabled
Using Read-only traffic type
Numa node
Numa node 0
0 63960.7
Measuring Loaded Latencies for the system
Using all the threads from each core if Hyper-threading is enabled
Using Read-only traffic type
Inject Latency Bandwidth
Delay (ns) MB/sec
==========================
00000 252.36 63847.1
00002 251.58 63870.3
00008 249.03 63503.5
00015 244.29 63487.7
00050 200.36 63665.9
00100 153.42 41987.0
00200 148.18 24408.4
00300 141.46 17256.4
00400 131.09 13866.0
00500 129.77 11338.9
00700 128.95 8394.1
01000 128.40 6104.3
01300 128.34 4838.1
01700 128.49 3830.9
02500 128.93 2770.7
03500 129.36 2122.6
05000 129.78 1634.5
09000 130.34 1126.0
20000 130.85 775.1
Measuring cache-to-cache transfer latency (in ns)...
Local Socket L2->L2 HIT latency 23.0
Local Socket L2->L2 HITM latency 23.3
mlc results for ABEF
Intel(R) Memory Latency Checker - v3.9
Measuring idle latencies (in ns)...
Numa node
Numa node 0
0 120.4
Measuring Peak Injection Memory Bandwidths for the system
Bandwidths are in MB/sec (1 MB/sec = 1,000,000 Bytes/sec)
Using all the threads from each core if Hyper-threading is enabled
Using traffic with the following read-write ratios
ALL Reads : 40977.5
3:1 Reads-Writes : 36990.5
2:1 Reads-Writes : 36611.3
1:1 Reads-Writes : 36264.7
Stream-triad like: 38313.1
Measuring Memory Bandwidths between nodes within system
Bandwidths are in MB/sec (1 MB/sec = 1,000,000 Bytes/sec)
Using all the threads from each core if Hyper-threading is enabled
Using Read-only traffic type
Numa node
Numa node 0
0 40982.3
Measuring Loaded Latencies for the system
Using all the threads from each core if Hyper-threading is enabled
Using Read-only traffic type
Inject Latency Bandwidth
Delay (ns) MB/sec
==========================
00000 294.43 41282.2
00002 294.65 41293.5
00008 307.92 41551.4
00015 306.20 41555.4
00050 277.07 41572.0
00100 181.10 40617.6
00200 155.25 24357.6
00300 151.21 17473.2
00400 146.21 13759.6
00500 144.90 11279.7
00700 142.36 8349.5
01000 136.65 6074.7
01300 135.69 4809.9
01700 135.06 3804.5
02500 134.54 2749.4
03500 134.37 2103.7
05000 134.30 1617.4
09000 134.27 1111.6
20000 134.41 762.2
Measuring cache-to-cache transfer latency (in ns)...
Local Socket L2->L2 HIT latency 23.0
Local Socket L2->L2 HITM latency 23.3
The difference is most pronounced for shorter inject delays, like 300ns vs 250ns. For idle latency, only 120 vs. 118. I tested with 3200MT/s.
This is likely the explanation why MB manufacturers recommend CDGH for 4 channels - for a normal fully populated EPYC it won’t typically matter, since you would either have 1 channel per quadrant, or exactly 2 of 4 quadrants will be without memory. But for a half-populated chip it does, as there are only 2 quadrants, and they better all have memory.
I believe I have read elsewhere that the 4-channel optimized chips always have the same “side” of the chip populated, but I can’t find it now. So my tentative conclusion is that CDGH is closer to one half, ABEF is closer to the other half, and it is always the CDGH half that is populated on 4ch-optimized chips.
Now I’m assuming that chip halves connect to two channels per side of the socket. I have not tested ABCD and EFGH memory configs, and I don’t know what to expect in terms of latencies if populating two channels from each of the halves of a 4ch-optimized CPU.
Thanks for the offer! I don’t really have any ideas for further testing at this time. @jtredux’s testing cleared up most questions I had about NUMA node number <-> memory slot pair mappings.
So I didn’t test this. Do you see a point that I do (given different MB)?
3 Likes
ROMED8-2T has only one DIMM slot per channel, so you should get full speed regardless. Usually the supported memory clock drops when each channel has two DIMMs, that is what Gigabyte seem to have worked around.
1 Like
I am trying to understand this I am total noob about RAM and speed/number of sticks - i asked the distributor and he said with Milan and AsRock if I get 6 sticks is about 60% performance I did not ask in what way but it even confused me more  I would love to have 64gig per stick but can’t afford them all 8 now - so I was thinking to get 2 or 4 but only if I don’t suffer with speed - like rendering in 3D? Or is it better for me to go 16gig x 8 all the way and populate them all? Still confused
I would love to have 64gig per stick but can’t afford them all 8 now - so I was thinking to get 2 or 4 but only if I don’t suffer with speed - like rendering in 3D? Or is it better for me to go 16gig x 8 all the way and populate them all? Still confused
Here is one interesting thing I just saw and I would like someone to explain if this observation is right. I see someone locally here is selling unused Dual-CPU AMD EPYC 7542 for 1500 EUR and my new sealed AMD EPYC 7443P costs 1233 EUR
so I was looking at cpubenchmark.net and I see that 7443P is A LOT faster then dual 7542 in single thread score 3,015 vs 1981 and in multicore score dual 7542 has an edge but its not scaling so well I see 70,935 for dual vs 59,036 for Milan.
Considering all this it looks like Rome is not a great buy especially for workstation users like me and prices are crazy high for Rome CPU but they don’t reflect the performance against Milan and I was socked when I saw that the guy i selling dual Rome for 1500 EUR unused because I saw that in stores single goes for 3850 EUR
So 7.7K vs 1.2K EUR for worse performance in single score and not so far off in multi score. Whats going on?
Talked to a guy I know at AMD and he told me this:
AMD allocates a number of processors per region: Americas, Europe, Asia, etc.
Lets say they allocated 1000 Processors in Americas and 1000 in Europe. How many major computer manufacturers do you know in Europe? I can’t think of any. In Americas I can think of Dell, HPE, and Lenovo that all are selling the 7003 models. They took the chip allocations for this region and can contractually continue to pillage future allocations based on demand (into 2022). If you want to get a 7003 in 2021 (or even 2022) you’ll have to get it in another geographical region and have them ship to the US. That is your only chance of getting one now or in the future UNLESS you are one of those three companies.
1 Like
Hi guys, new poster here, just pitching in with my setup:
- Asrock Rack ROMED6U-2L2T
- EPYC 7402P 24-Core Processor
- 128GB ECC Unbranded DRAM 2x32GB, 4x16GB, the ROMED6U has 6 dimm slots)
- Proxmox VE as main OS
- Radeon XT 5700 passed through my main Windwos WM (for Gaming)
- Sapphire GPRO e9260 8 GB passed through my main OSX VM (for Working)
- 2x Fresco Logic FL1100 USB 3.0 Host Controllers, passed through either my main VMs, connected using two of the ROMED6U Slimline connectors to external PCIe 8x slots
- 1x Dual 2X NVME M.2 AHCI x8 adapter, bifurcated to 2x 4x NVME ssds
- 1x 4x NVME Pci Adapter
- OS running from the onboard NVME slot
I am using the 7402P configured as a single numa node:

and since both my main VMs require as low latency as possible I am pinning KVM threads to single cores, and shielding them from the main OS threads.
The OSX machine has 8 dedicated threads, while the Windows VM has 12, I also pin and isolate the emulator thread for perfromance reasons, and isolate the VM interrupts as well. I will be posting the details in a separate thread
I am running the Milan beta BIOS L3.01 even if I ended up with a Rome CPU (the plans where to get a 7443P), but availability in the past months has been nonexistent, and after two orders that were voided, one of which I still have to get my money back, I ‘settled’ on the 24 core rome part
I am running ‘in production’ since a couple of weeks, and have been fiddling with the system for a couple of months now
System is Air cooled with
- 1x Noctua NH-U9 TR4-SP3
- 2x Noctua NF-A14 PWM in pull configuration
- 2x 200mm Thermaltake FAns in push configuration
I am using 2x Thermaltake V21 cases stacked, could have probably fit everything into a single V21, but thermals would have been horrific
Since I am running proxmox on the main system and passing through all the GPUS I am controlling the initial start of the VMs using a Streamdeck:






So far a very happy camper, the only ‘problem’ I have encountered is that my 16GB dimms (all four of them) are not seen by the BIOS, but are seen and usable by the OS … have tried to contact asrock support but gotten a silly answer back …
4 Likes
No, not really. I think you’ve done enough. Thank you, man ! 
1 Like
Welcome, @MadMatt ! Nice to have you here, the more the merrier ! 
I’ll be sure to look for it, I’m very interested. I’ll keep my questions until then.
For the vast majority of workloads, including rendering, 4 channels with a 7443p is definitely enough. Even 2 channels might be enough, but I’m not as sure about that.
You mention 3D rendering, but will you do that on the CPU? Since GPUs usually do it better - however I don’t know whether they are still that much better with today’s prices.
Edit: Ok I see now you mentioned GPU vs CPU earlier in our discussion, and that you use both. I believe 4ch will still be enough, but you can always do as I suggest below and make a thread about your specific workload. There are many around here that seem to be good at bandwidth math
I suggest you describe in more detail what you plan to do with your machine, particularly the tasks that are important for you to do fast. That could even be a topic for a thread of its own, since there are probably many experts in the forum that know a lot about what different tasks require, but they might not follow this thread since it is focused on specific chips.
For workloads like rendering, bandwidth is more important than latency. Bandwidth scales with number of memory channels, but only until the compute units (be it CPU cores, GPUs, or whatever) are saturated and work with full speed. Then the memory will have to wait anyway. Excess bandwidth is useless.
You can also think like this. A 7443p has 24 cores. The largest Milan chips have 64. AMD thinks that 8 channels is enough for those chips. That is 8 cores per channel. For your 7443p, with 4 channels of memory you would have 6 cores per channel. So your cores will still be better fed with data compared to the top Milan chips.
Demands are slightly different if you need low latency. Latency can be improved by tying specific memory channels to the CPU cores that are physically closest to them, this is done with the NPS setting (“NUMA Nodes Per Socket”) in the BIOS setup. This is also what we have been discussed most in this thread, when discussing memory optimization. If you do this, then 4 channels have some drawbacks compared to 8, but the drawbacks can be mitigated. Either way this will not be important if you mainly do rendering.
Sounds a bit scammy to me, especially if it is a full machine.
1 Like
Wow, very interesting build, thanks for posting!
I am considering building a Rome-based VM and file server around that particular motherboard, ROMED6U-2L2T. That would be based on my current CPU, a 7252, after I upgraded my current H12SSL-based rig to Milan (likely 7313p) some time later this year. Then I’ll know who to ask for tips
Also nice to see a GPRO card in production. I have the GPRO 4300 (roughly the same as Radeon wx4100). However I did have some problems with it, but I think I’ll wait for your other thread before asking about your experience with yours, as to not make this thread longer for off-topical reasons
1 Like
Thanks @Nefastor , I have created a separathe thread here Epyc on Asrock ROMED6U-2L2T - Proxmox Build
1 Like
@oegat , I had the 7252 for about a month while waiting for the 7402P (thanks Amazon) and other than the limited number of cores that would not let me isolate safely the two low latency VMs it performed egregiously, with better thermals and power consumption compared to its bigger brother …
As for the GPRO card, it was the best solution I could find for a dedicated GPU that used only one slot and was natively supported in OSX … the only downside being the scalper price I had to pay for it
1 Like
The 7443P pricing is very much an outlier though - it’s $1337 - just to spell out leet ! The 1/2 socket version is $2010 by comparison, and the 7443P is actually cheaper than the 7343 16-core/32 thread.
STH has some good tables in its article:
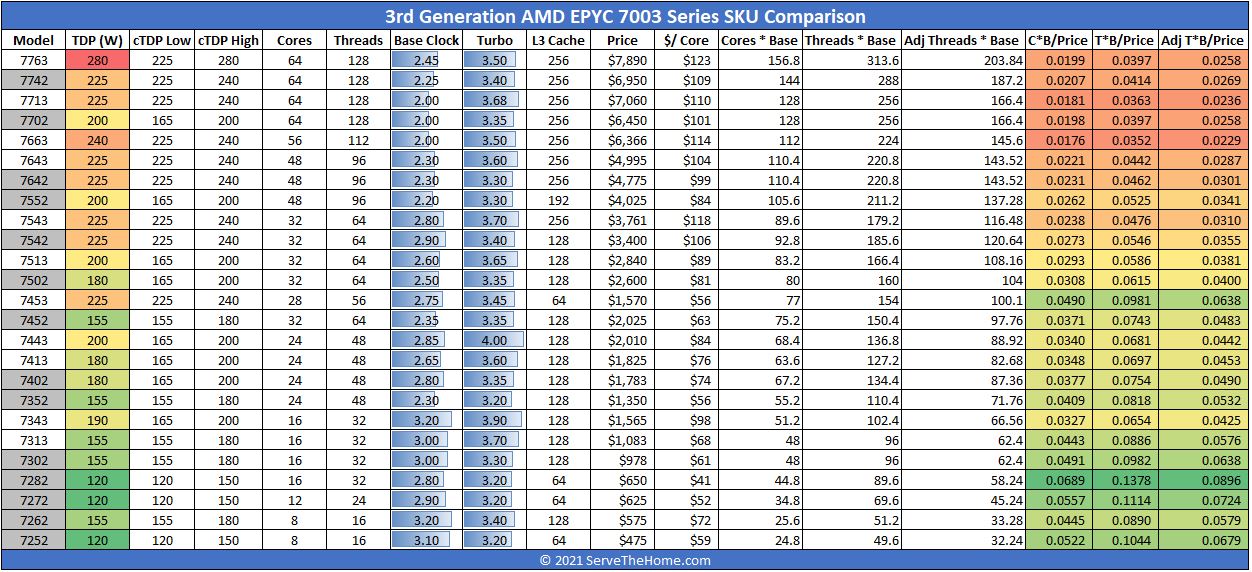{kind=link}
TBH all my server-boards do this, it’s just that most of my other servers have Noctuas, not 7.5K rpm monsters. I really wouldn’t want to put a finger anywhere near these case fans - ‘will it blend?’
On a warm boot, this fan ramp dies down after ~10s, then it drops to a mere 58dB for ~1 min, before settling to idle (my office is ~48dB anyway due to the other machines), but you really wouldn’t want to share an office with anyone who had this under their desk, unless they never turned it on/off.
1 Like
Well this is just the SKU but does not tell us anything about performance jumps and especially for use cases where turbo clocks of .5ghz more destroy Rome CPUs in all benchmarks especially in single core for apps like after effects, 3d simulation and so on.
For me both latency and raw bandwith performance is imprtant as different apps use it differently, that is why I think this 7443P is amazing value when you compare it to what you get on threadripper pro and destop cpu.
I think i will settle for 4 sticks and add 4 more later