Let me rephrase that: since it’s an U.2/U.3 connector pinout issue, the Adaptec HBA should be fine with the U.2 drive as long as you have the right cable (MiniSAS → 2x U.2). U.3 cables won’t work, but U.2 should. That Amazon one looks pretty janky though.
2 Likes
Thanks for the help everyone! I ordered the correct u.2 cables. Let me know if anyone needs the u.3 ones I have… ![]()
I’m unsure if this is the correct thread, but my issue concerns PCIe. My main rig has been having constant problems with the LAN adapter on my ASRock X670E Taichi; it would stop working whenever high traffic passed, i.e., downloading a game on Steam. Even pinging the router’s local IP would take 1000ms+ after the issue occurred, and the only way to fix it was to restart the device. I tried many different drivers, advanced driver options in the device manager, power management, etc, but nothing worked. I’m pretty sure it is a faulty onboard NIC. Thanks, Killer!
Any way to bypass this issue, I picked up an ASUS XG-C100C PCIe NIC. It works great; however, the only problem is that my 4090 runs in PCIe 4.0 8x mode (it was running 16x before installing the NIC).
This is the part where I get confused; the motherboard claims to have two PCIe 5.0 16x slots, which I believe falls back to 8x if both slots are consumed. So, from my understanding, if the motherboard switches to PCIe 5.0 8x on both slots, doesn’t that mean the 4090 should still be able to run at PCI 4.0 16x, as that is the equivalent speed of 5.0 8x?
I tried messing with the AMD PBS bios settings, forcing the second slot to run at Gen 3 (which the NIC requires); however, nothing seems to work, and the GPU is still running at 8x. The BIOS also has a Chipset Link Speed option, but I don’t think that will help either.
Any suggestions?
This sounds kind of like the infamous I225-v silicon bug, pretty sure the killer nic is just a rebranded I225-v so it stands to reason it could have the same defect.
unfortunately not, the PCIe host will have to downgrade to the speed the PCIe peripheral runs at even if it had “spare” bandwidth. and there is no solution to mux PCIe lanes out short of a PCIe switch which are very expensive and buggy at the same time.
2 Likes
-
It sucks that the ASRock X670E Taichi doesn’t have a third PCIe slot that gets its PCIe lanes from the chipset.
-
Maybe the original issue is solvable: Try to find out where exactly underneath these stupid metal plates the motherboard’s onboard NIC chip is located and blast that area with a fan.
-
If these metal heatsinks don’t make contact with the chips they act like insulators trapping air so no case airflow gets over the NIC for example - your issues sound like a NIC overheating.
-
Just to be sure, have you tried using the latest Intel drivers for the NIC? Download and decompress this package and let Windows look for drivers in the folders via Device Manager:
- If that doesn’t help and the dedicated ethernet adapter is to stay you could “harvest” PCIe lanes from M.2 slots for the ethernet adapter via cables and adapters which can be a bit tricky but should be doable with PCIe Gen3, the ASUS XG-C100C is PCIe Gen3 x4.
2 Likes
Yup, I regret it so much. I have been trying everything to avoid an RMA, but it’s looking like that will be the eventual route.
Interesting, I haven’t seen this theory before, and I’ve been through so many different pages trying to troubleshoot it. I’ll see if I can give that a go at all. Although ambient temps in this case are very low, I have a lot of cooling.
Edit: Taking a look at the metal block, I feel like I would probably have to void the warranty to get it off.
Yup, I’ve avoided all the killer software, manually extracted drivers from the package and messed with so many different “power saving” options, etc, that are supposed to fix the issue, but nothing has worked.
I did think about this, but it sounds like such a messy road to go down, although I wonder if a simple USBC ethernet adapter could work. I don’t need the 10G speeds. Something like 2.5G would also be acceptable.
1 Like
To clarify the reply by @twin_savage,
The are a limited number of PCIe lanes that come from the CPU.
With Ryzen 7000 series, the number is 24 lanes electrically.
4 lanes go to the PCH.
4 usually go to a m.2 slot.
The remaining 16 lanes are then divided up depending on configuration.
Lanes are lanes, regardless of PCIe version.
If I have a GPU in slot 1 and another x16 card in slot 2, then the remaining 16 lanes from the CPU are likely going to be divided up as 8x in slot one and 8x in slot 2 unless I instruct the mobo otherwise.
If the mobo supports it, you can set it up as 8x in slot 1 and 4x+4x in slot 2.
On page 11 of the manual PDF file the location of the LAN chip is roughly “next to” the Y axis position of the 3.5 mm audio ports of the back panel:
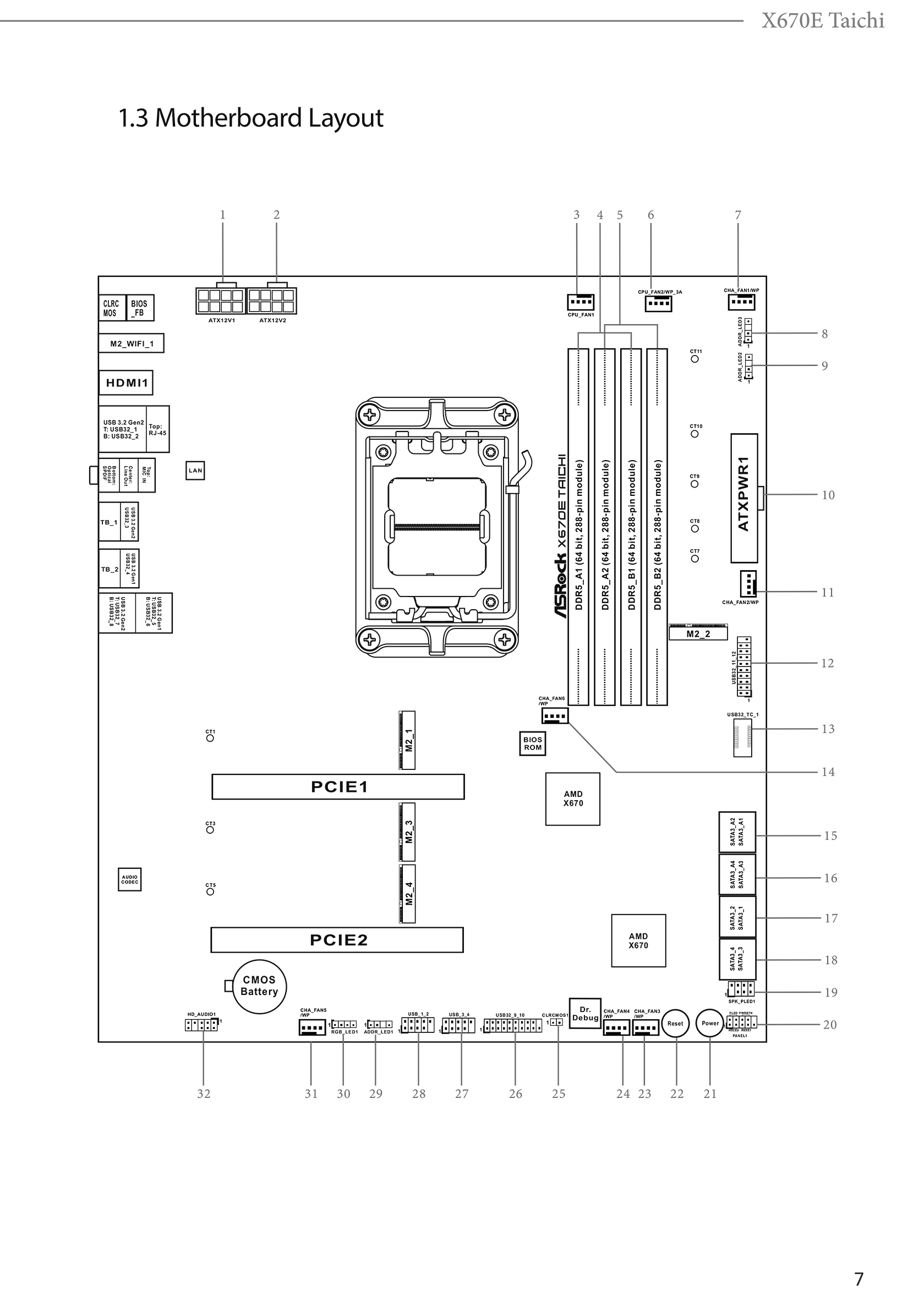
Try to force air with high static pressure under the lump of metal that’s over that area. It’s a real nasty trend since pockets of air that isn’t moving are as mentioned great insulators to concentrate heat even from low-powered devices that wouldn’t have any issues if they were simply “open-air”.
- Regarding 2.5 GbE USB-C dongles, I have some for portable devices, are there any specific tests you want to know the results of?
2 Likes
I have an option for that; however, I figured that would still cap the GPU at 8x Gen4.
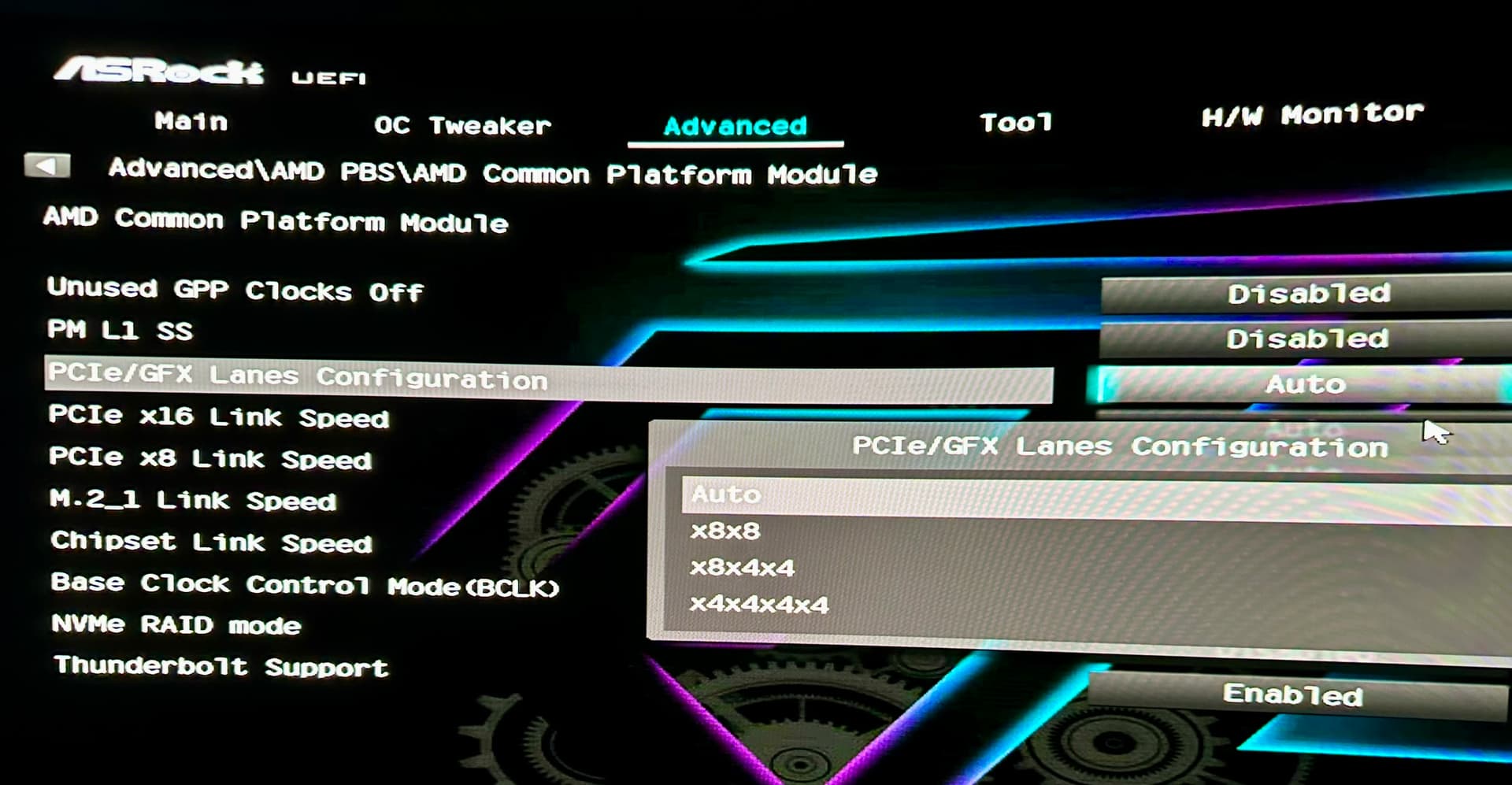
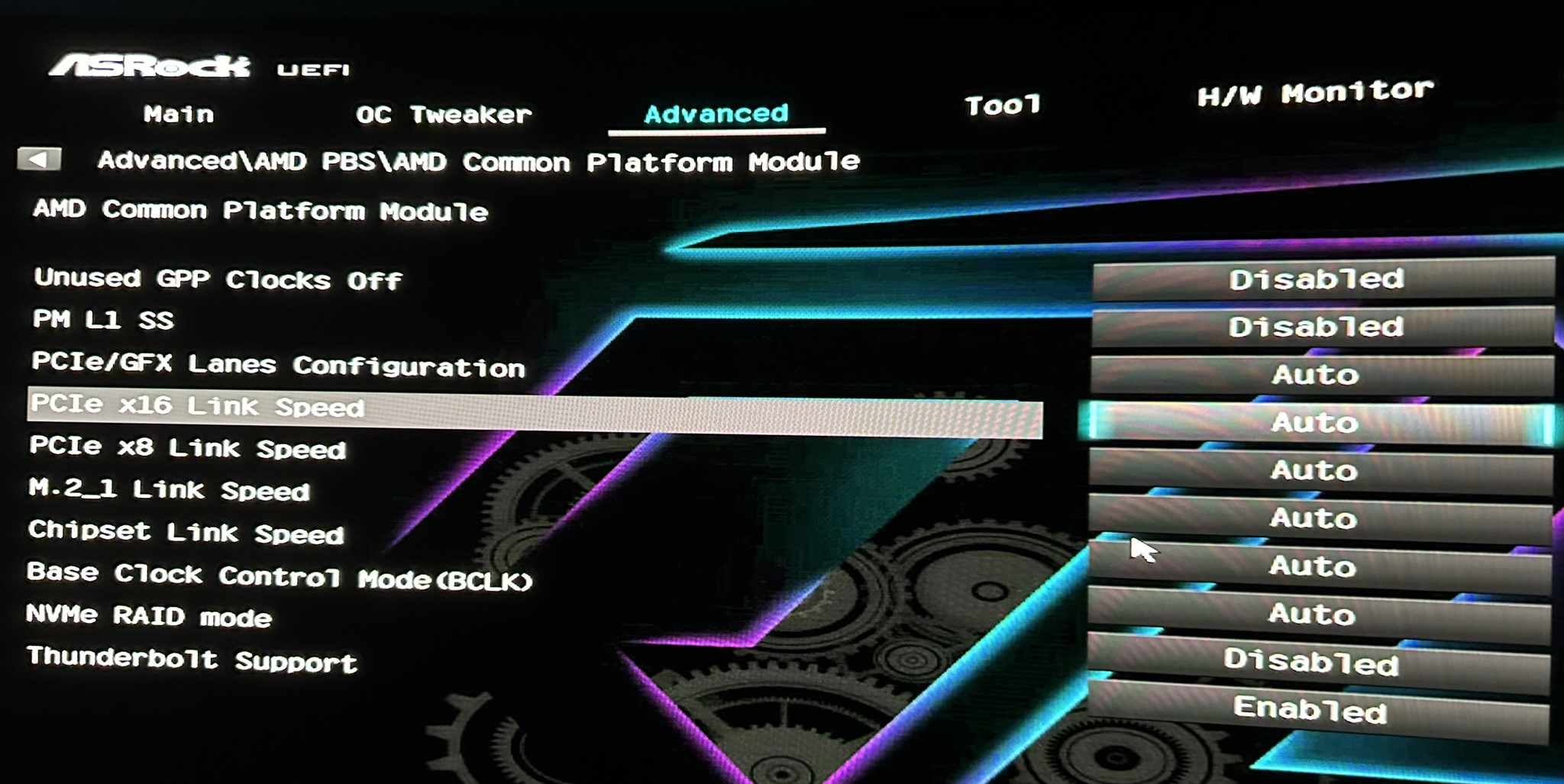
I would just be looking for something stable over a long period, as it will be the primary NIC for the PC.
I plugged mine into the Thunderbolt 4 port of my daily AM4 system to use it for a while on a more powerful computer. If I won’t post anything about it that means there weren’t any (negative) surprises.
The one thing I made sure of is to only get ones with a metal case to help keep temperatures down.
Currently working fine at 2.5 GbE with a MikroTik 10 GbE switch.
This whole thread is really making me nervous about trying to build an NVMe-based test platform for work. I proposed internally a project to put together a home-brew system based around the ASRock Rack ROMED8-2T and a 32-core EPYC Milan 7543P CPU so that I could hook up a bunch of PCIe 4.0 NVMe drives (either Kioxia CD6 read-intensives or a bunch of Samsung PM9A3s) in a couple IcyDock ToughArmor MB118VP-B bays. I assumed by using some re-timer cards (since the ROMED8-2T definitely supports 4x4 bifurcation on all slots) and relatively short SFF-8654 to SFF-8654 cables (0.5m in a mid-tower case would probably reach, right?) I wouldn’t encounter issues.
Now, having skimmed this entire thread, I’m not so sure about this plan. Maybe it’s better to just get a proper all-NVMe server from Supermicro and forego the homebrew route? It’s surprisingly not even that much more expensive to get a dual-socket Genoa system from them. Which is to say, it costs more without any NVMe drives than my proposed testbed system does with NVMe drives and a small A2000 12GB GPU. But still, we’re talking, like, “within a couple thousand bucks”, not “twice the price”.
What says the forum? Intended use would be testing all manner of stuff, mostly Linux but maybe some Windows Server stuff too, VMs via ESXi or Proxmox, TrueNAS/Unraid, md or MinIO on Linux, basically anything I can think of that might be interesting to try with 12x drives of CPU-attached, PCIe 4.0 NVMe and a bunch (at least 256GB) of ECC RAM.
2 Likes
You might be surprised between eyeballing it and actually attempting to do so. I had a 50 cm cable from another inactive machine I borrowed parts from, and used it to measure the true length required. Turned out my cable needed to be 55~60 cm for the other machine. The thing that sucks is that lengths between 50 and 100 cm are pretty uncommon on the market.
As the crow flies, the distance might be within 50 cm, but the cables can be pretty stiff and almost never take a direct path from port to port.
1 Like
That makes sense, but given all the problems people have had with longer cables… or is that only when talking about entirely passive solutions? AKA, simple PCIe cards that offer no retiming, just electrical connections to the proper slot pins running to the proper connector pins, and then no powered backplane on the other side, just powered U.2 drives?
Basically, have people gotten PCIe 4.0 speeds with 80cm–1m cables working as long as they have active cards (whether tri-mode or simple re-timers)? Are most of the problems around passive-only solutions?
2 Likes
I’ve only done PCIe 4.0 SSD testing with ICY DOCK enclosures, OCuLink cables, and M.2-to-OCuLink adapters on a Ryzen 7000 build. Basically:
- 25 cm & passive adapter works. Once in a blue moon though, the negotiated speed drops to PCIe 3.0.
- 50 cm & passive adapter results in WHEA (
 ) events—either more or less depending on which slot is used.
) events—either more or less depending on which slot is used. - 50 cm & redriver adapter works.
I’ve had PCIe 3.0-rated 75 cm cables tested with PCIe 4.0 SSDs, but via chipset lanes (so there was no error reporting). The sequential read performance dropped by 15%, which is something I also saw with prior tests where I could see WHEA events. I didn’t have any other traffic competing for chipset-to-CPU bandwidth. My gut feeling is that a 75 cm PCIe 4.0-rated cable with a redriver could work at that length, but nobody sells such a cable.
1 Like
I guess this is not that surprising. Obviously the OEMs can get manufacturers to make cables to their specs to support the runs necessary to get from PCIe cards (or motherboard-mounted ports) to the front backplanes in their 24-drive NVMe storage servers—runs which have to be longer than half a meter—but I guess the economies of scale aren’t there to sell similarly specced cables to end users. Still, strange to me that clearly they exist but just aren’t available.
3 Likes
You now have understood the essence of the quest within this thread - WELCOME!

5 Likes
Bummer… it turned out that was a switch combination I tried already. I just tried it again. The LEDs are on, but the SSD isn’t detected. I may have a dead adapter …4 days past Amazon’s return window. ![]()
EDIT: just to note: my adapter came with the correct jumper setting and I never had to change it. The switches with the protective film removed in your photo were the ones I played with.
1 Like
Serve The Home does excellent write-ups on networking equipment. Multi-Gig USB dongles with long term stress tests included.
2 Likes
For those who have one of the Adaptec HBA 1200 series HBA (no RAID controller), I’m curious about a few things:
- Are NVMe SED functions accessible directly or indirectly through Adaptec’s own utilities? I know their RAID adapters have the feature, but their documentation is not clear on native NVMe SED support for the HBAs.
- Are low-level NVMe formats to different sector sizes with metadata possible? If so, can Linux read and write sector metadata on such SSDs behind the Adaptec HBA?
- Are compound PCIe-connected devices (e.g., multiple SSDs behind a switch, which are then connected to the HBA) fully usable? (I am guessing not.)
- Are non-SSD PCIe devices connected to the HBA accessible? (I am guessing not for this one also.)
I’ve read from prior posts that even the NVMe SSDs are exposed as SCSI devices. That doesn’t really matter for NAND as long as the exposed devices have the same features. #1 and #2 are important; the Broadcom P411W-32P, which is NVMe-only already supports those scenarios by default. The Adaptec HBA’s ability to connect 8 U.2 SSDs per SlimSAS 8i connector would put it ahead of the Broadcom solution.
I’d imagine that would depend on where you want storage device management to live and the features you’d like to make use of…
On and handled by the HBA?
Or
Motherboard FW?
Or
Operating System?
I can theorize (and possibly see) why Adaptec went down the route of (what appears to be) HBA FW management instead of the other options listed options. Eg.: In the event NVME (PCIe) hot-swap is not (fully) supported by HW, FW, or Software.