Soooooo… With the PTI patches affecting performance of applications using massive amounts of I/O, (and sharing framebuffers is a massive amount of I/O) I was wondering about Looking Glass benchmarks across different configurations pre and post patch. We know NVMe performance took a noticeable hit, what about Looking Glass?
SUCCESS! OBS capturing the Looking Glass client window in borderless fullscreen using “Window Capture (Xcomposite)” gives me exactly the result I was expecting. Now if only there was a direct plugin for it to be a source, that would remove the overhead of trying to grab it from Xserver.
It runs a bit slow, likely because I have not properly implemented the IVSHMEM PCI Bar access in linux, but it shows that it is indeed possible!
It should also be noted that evdev suffers the same problem with the PS2 mouse input issues the spice client sufferes. My Linux Guest is using evdev and this keeps popping up in the dmesg output:
[ 5151.284682] psmouse serio1: Explorer Mouse at isa0060/serio1/input0 lost synchronization, throwing 3 bytes away.
[ 5453.640527] psmouse serio1: Explorer Mouse at isa0060/serio1/input0 lost synchronization, throwing 1 bytes away.
[ 5460.772483] psmouse serio1: Explorer Mouse at isa0060/serio1/input0 lost synchronization, throwing 1 bytes away.
[ 5495.299821] psmouse serio1: Explorer Mouse at isa0060/serio1/input0 lost synchronization, throwing 1 bytes away.
[ 5673.238549] psmouse serio1: Explorer Mouse at isa0060/serio1/input0 lost synchronization, throwing 3 bytes away.
[ 5863.004505] psmouse serio1: Explorer Mouse at isa0060/serio1/input0 lost synchronization, throwing 2 bytes away.
[ 5943.676411] psmouse serio1: Explorer Mouse at isa0060/serio1/input0 lost synchronization, throwing 1 bytes away.
I only just figured out that Nvidia driver 384.111 works if kvm=off is used on Ubuntu 17.10.1. Maybe that’s worth testing? I have a Kubuntu Guest and I want to do Looking Glass from Linux Guest to Linux Host.
I have never had any code 43 issues, and I have always run with kvm=off, which btw, doesn’t turn off kvm as the name implies, it just hides the signature from the guest.
Been debugging why LG is so slow in the guest and it looks like some strange memory performance issue with guest memory access in QEMU.
# for I in `seq 1 32`; do ./a.out $I; done
1 MB = 0.026123 ms
2 MB = 0.048406 ms
3 MB = 0.073877 ms
4 MB = 0.096974 ms
5 MB = 0.115063 ms
6 MB = 0.139025 ms
7 MB = 0.163888 ms
8 MB = 0.187360 ms
9 MB = 0.203941 ms
10 MB = 0.227855 ms
11 MB = 0.251903 ms
12 MB = 0.279699 ms
13 MB = 0.296424 ms
14 MB = 0.315042 ms
15 MB = 0.340979 ms
16 MB = 0.358750 ms
17 MB = 0.382865 ms
18 MB = 0.403458 ms
19 MB = 0.426864 ms
20 MB = 0.448165 ms
21 MB = 0.473857 ms
22 MB = 0.493515 ms
23 MB = 0.520299 ms
24 MB = 0.538550 ms
25 MB = 0.566735 ms
26 MB = 0.588072 ms
27 MB = 0.612500 ms
28 MB = 0.633682 ms
29 MB = 0.659352 ms
30 MB = 0.690467 ms
31 MB = 0.698611 ms
32 MB = 0.721284 ms
Linux Guest Output
$ for I in `seq 1 32`; do ./a.out $I; done
1 MB = 0.026120 ms
2 MB = 0.049053 ms
3 MB = 0.081695 ms
4 MB = 0.126873 ms
5 MB = 0.161380 ms
6 MB = 0.316972 ms
7 MB = 0.492851 ms
8 MB = 0.673696 ms <-- ok, getting slower...
9 MB = 0.221208 ms <-- what the hell, faster to copy an extra MB??
10 MB = 0.256582 ms
11 MB = 0.276354 ms
12 MB = 0.316020 ms
13 MB = 0.327643 ms
14 MB = 0.363536 ms
15 MB = 0.382575 ms
16 MB = 0.401538 ms
17 MB = 0.436602 ms
18 MB = 0.473452 ms
19 MB = 0.491850 ms
20 MB = 0.527252 ms
21 MB = 0.546229 ms
22 MB = 0.561816 ms
23 MB = 0.582428 ms
24 MB = 0.614430 ms
25 MB = 0.660698 ms
26 MB = 0.670087 ms <-- Finally we are as slow as 8MB
27 MB = 0.688908 ms
28 MB = 0.714887 ms
29 MB = 0.746829 ms
30 MB = 0.763404 ms
31 MB = 0.780527 ms
32 MB = 0.821888 ms
This is a direct memory to memory copy… and on bare metal it performs consistently. It should not be a matter of block size, something is broken in Qemu’s memory management.
Sorry but im rather confused with the dual guest post you put out not that long ago?
Did you manage to run it off one gpu, and somehow getting SR-IOV to work on non enterprise software?
Or are there two gpus in the system, or am I completely missing the point? (The latter is very much possible)
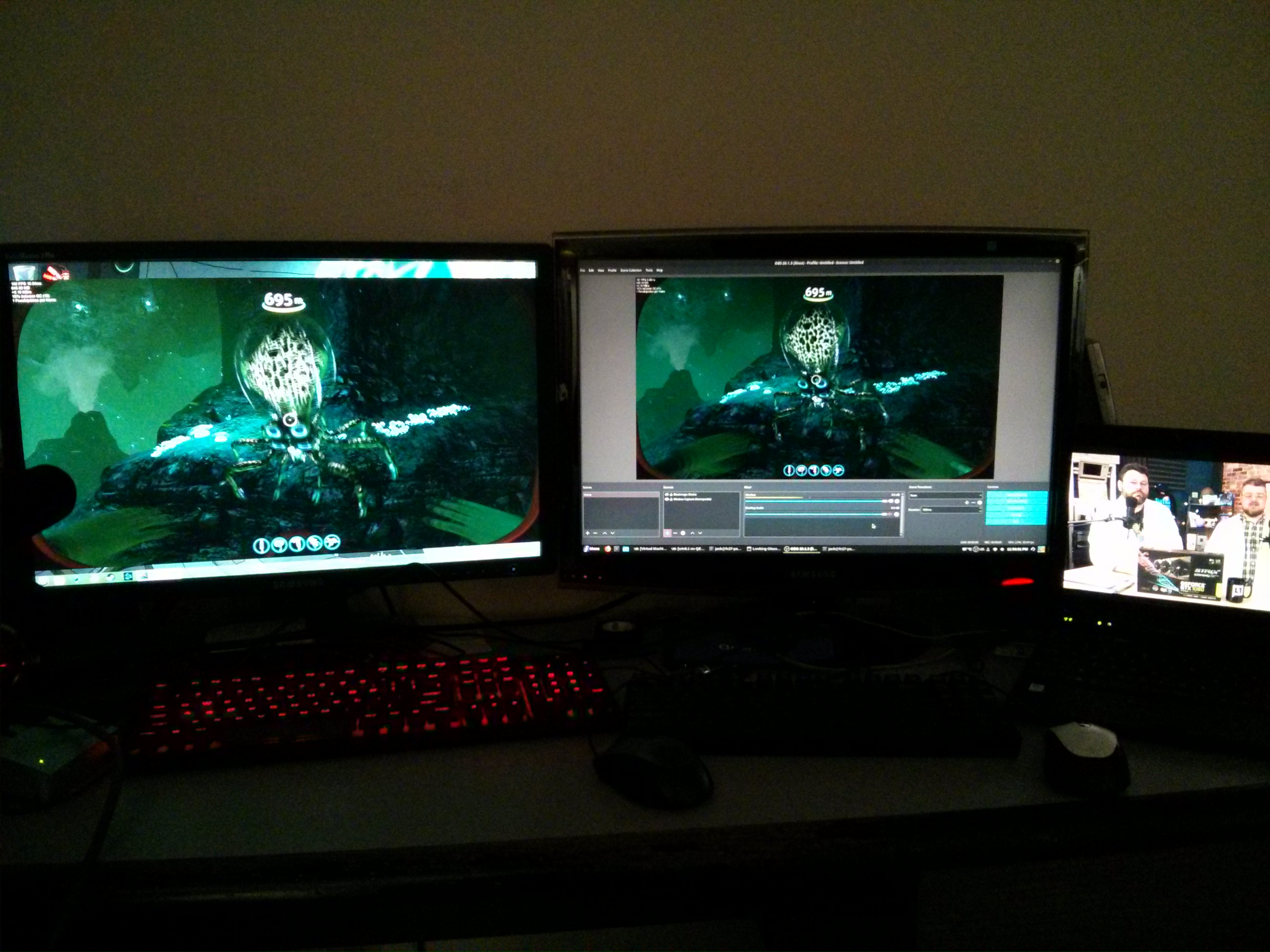
I will be streaming Subnautica in a Windows 8.1 VM with the Looking Glass host using Looking Glass client + OBS on the host. I made a test stream and it is fully production ready with no frame drops. I think some of my frame drops on recording were due to a slow hard drive.
If people are interested, I may be doing it Sunday night on Twitch. jack_vancouver is the username.
Also, protip, DON’T use your scroll wheel in OBS settings boxes cause it can accidentally hover over a critical value “like GPU # for NVENC” and you will spend hours thinking a CUDA update broke it again.
Nice! I have spend the last few days tuning my TR system to run windows along side a VM for work, etc… My test platform has been Subnautica also
I found that if I change the memory mode in the bios to “Channel” to expose the NUMA architecture to the OS, and use numactl to launch qemu I can force it to use only cores on one die, and force it to use local RAM to that die. The performance is outstanding! I highly recommend those that have a TR to do this rather then just pinning cores.
Btw: Subnautica no matter what I do, bare metal or not, has frame drops when loading in assets.
That’s very handy! Isolating resources to a single die helps a ton when I consider Threadripper down the line. Stream will start in 30mins barring any issues.
Bare Metal intel i9 7900x @ stock speeds everything, no xmp (fedora 27, quadchannel gskill)
for I in seq 1 32; do ./a.out $I; done
1 MB = 0.050926 ms
2 MB = 0.080167 ms
3 MB = 0.146383 ms
4 MB = 0.162551 ms
5 MB = 0.203779 ms
6 MB = 0.261949 ms
7 MB = 0.294054 ms
8 MB = 0.324649 ms
9 MB = 0.363344 ms
10 MB = 0.401900 ms
11 MB = 0.468520 ms
12 MB = 0.498136 ms
13 MB = 0.524811 ms
14 MB = 0.561727 ms
15 MB = 0.604771 ms
16 MB = 0.644404 ms
17 MB = 0.686897 ms
18 MB = 0.770282 ms
19 MB = 0.810386 ms
20 MB = 0.870343 ms
21 MB = 0.901968 ms
22 MB = 0.956122 ms
23 MB = 1.003841 ms
24 MB = 1.042294 ms
25 MB = 1.084547 ms
26 MB = 1.130444 ms
27 MB = 1.170370 ms
28 MB = 1.215668 ms
29 MB = 1.258736 ms
30 MB = 1.302627 ms
31 MB = 1.343505 ms
32 MB = 1.391565 ms
Kernel 4.13.12-300.fc27.x86_64
this is fedora 27 with 2 vcpus and 4gb ram:
for I in seq 1 32; do ./a.out $I; done
1 MB = 0.062563 ms
2 MB = 0.093608 ms
3 MB = 0.136903 ms
4 MB = 0.181300 ms
5 MB = 0.226185 ms
6 MB = 0.266328 ms
7 MB = 0.313482 ms
8 MB = 0.347752 ms
9 MB = 0.393641 ms
10 MB = 0.438925 ms
11 MB = 0.482291 ms
12 MB = 0.520403 ms
13 MB = 0.555277 ms
14 MB = 0.595446 ms
15 MB = 0.641180 ms
16 MB = 0.691243 ms
17 MB = 0.741690 ms
18 MB = 0.771237 ms
19 MB = 0.810897 ms
20 MB = 0.854591 ms
21 MB = 0.898990 ms
22 MB = 0.938643 ms
23 MB = 0.986541 ms
24 MB = 1.034960 ms
25 MB = 1.074709 ms
26 MB = 1.117146 ms
27 MB = 1.154235 ms
28 MB = 1.199121 ms
29 MB = 1.254363 ms
30 MB = 1.279912 ms
31 MB = 1.324578 ms
32 MB = 1.369045 ms
Linux localhost.localdomain 4.13.9-300.fc27.x86_64 #1 SMP Mon Oct 23 13:41:58 UTC 2017 x86_64 x86_64 x86_64 GNU/Linux