Guys, an update:
Basically this whole Prime95-stability issue has been resolved on a technical level, but it is not out yet. So if you were uncertain to buy a Threadripper or Gigabyte-MoBo, dont be, its fine.
- The VRM issue was real. Gigabyte has a fix. (as expected)
- The P95-stability issue was not only due to the VRM-flaw but also because of an AGESA-flaw.
BOTH issues cause P95-instability. This was confusing to diagnose since people with- and without the VRM problem may have experienced problems.
I first believed that all systems that crashed must have had the VRM-issue - but that wasnt the case. I initially thought it was a measurement mistake or just a hard-to-measure level of VRM-misbehavior. (If crashing systems were diagnosed with “good” VRMs)
To anyone who observed the Gigabyte Bios releases, this was a funny to watch chaos over the last few days.
Basically any Bios version F4x is flawed (old AGESA, no VRM fix; which does not mean your system is inherently unstable, but it could be )
Then Gigabyte came out with F5b which fixed the VRM bug. But to the anger of AMD this was an uncoordinated release and did not include the new AGESA version which would have fixed all problems at once. So Gigabyte pulled F5b and pushed F5c (which is currently the most recent Bios online). This Bios has now the new AGESA to fix P95, but funny enough, it does not include the VRM fix.
I am pretty sure, that quite soon, there will be a F5d-bios or something that will include both fixes and “everything just works”.
Once this is out, the Vcore will look like this:
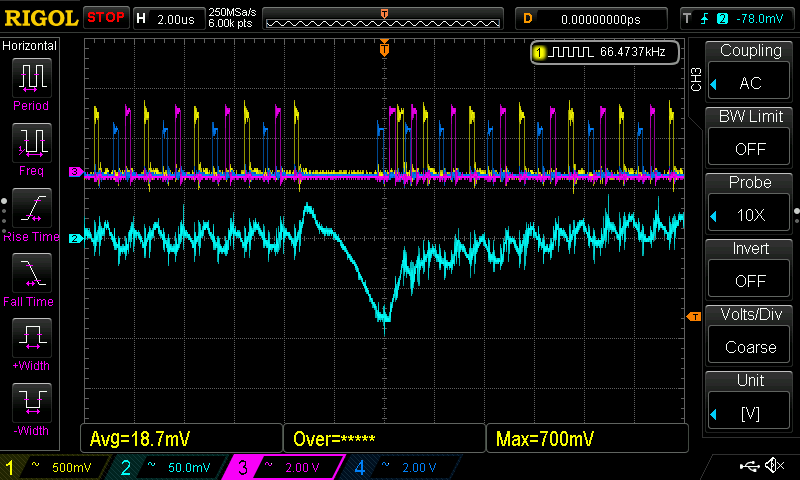
THIS IS PERFECT! (captured with the short-lived F5b bios; P95 was still crashing due to AGESA-problems)
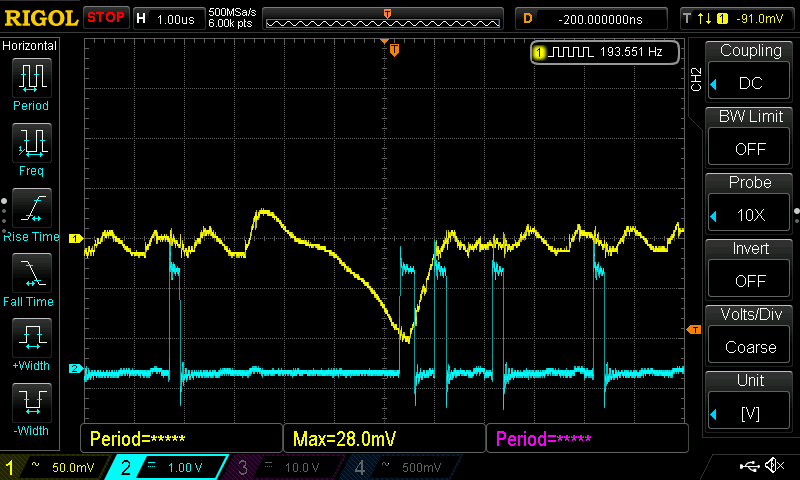
As a reminder, a load decrease (the voltage jump you see above) caused missing switching cycles before, during which the low side mosfets were turned on, resulting in a violent discharge of Vcore. Here is some detail:
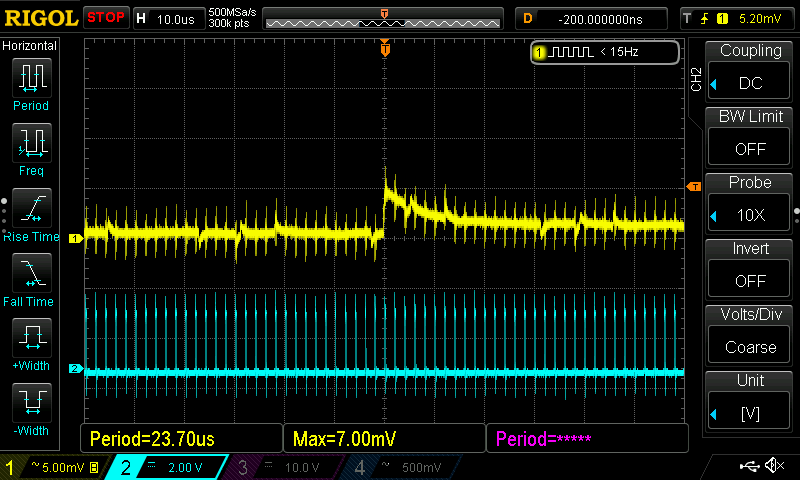
(Captured with the current F5c-bios)
I am currently staying on the F5c bios since the new AGESA version does make my PC more stable in light-load scenarios. I am currently running 60h without crash (the age of F5c) - this was unthinkable before.
However under high load the VRM bug still causes CPU-failure.
Again, i think this will be fixed very soon (it should be trivial). So everything is good.
What was it like to work with AMD?
Well, there was no working WITH or FOR them. Its a big company with big policies - it is pretty much a one way communication. No juicy details leave AMD, which at times was quite annoying; specially as an interested engineer, i would have preferred some details-but-not-details, basically a summary for idiots at least. The one way communication left me quite frustrated at times - especially when AMD hinted that they werent completely sure if they addressed the right issue or not (they did). But it sparked the urge to help or double-check, which was impossible. (Those issues are all about replicating the original problem which can be extremely hard, specially if the problems are statistical in nature and only communicated via email in written form in English as a 2nd language)
AMDs motivation to solve the issue was/is crazy high. People really care to provide a good product and a good experience. The only thing that bothers me is how broken the customer support is - i guess it is fine when you have a normal RMA but true technical issues dont come through.
The fact that this issue was solved so quickly seems like a big coincidence. (Thanks forum!)
It boggles the mind what AMD can do with software configuration to their processors. Those systems are incredible if you even try to understand the details that must go into them.
All in all a super cool experience 
 )
)